This guide is tailored for developers working with OpenPype, particularly during the initial phase of transitioning to AYON. It provides instructions on how to develop Pyblish plugins for OpenPype’s pipeline.
If you’re looking for information on AYON Addon Development, please refer to the AYON Addon Development | AYON Docs.
Introduction
Walking through this guide to learn about how a new product-type support is added to AYON/OP.
Publish plugins are DCC specific but they follow the same structure.
I will give examples from Houdini because I don’t like using arbitrary examples.
So, consider finding the respective methods in other DCCs
Publish Process is built on top of pyblish where:
- you mark a group of data with special marks using a creator tool
- continue work as usual
- on publishing, the publish tool will
a. look for those groups with special marks and list them as publish instances
b. run some checks to validate these data
c. export these groups if passed checks
d. run integrator tool if export was successful - integrator tool will move and rename exported data
- post integrating plugins
Visualization:
Key concepts
What is publishing?
In simple words, it’s about exporting your work and share it with colleagues.
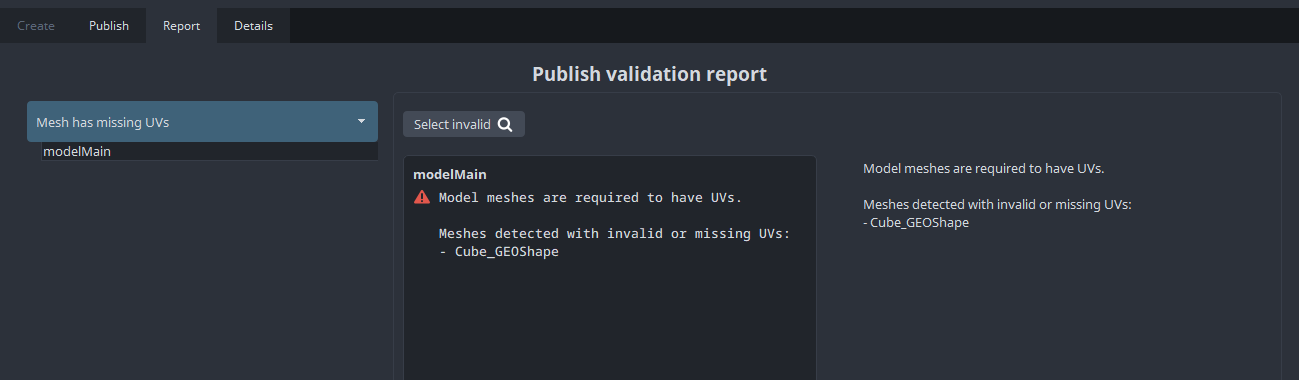
However, one key component in the publish process is the validation process so that errors can be caught early before exporting and sharing any work, e.g.
-
A
Modelproduct in Maya should have UVs to pass Mesh Has UVs validation.
Modelproduct is one of the implementedproduct-typesin AYON
If you are curious, here’s a list of implemented product-types(families)
The ![]()
pyblish component with AYON wrappers and other top level functions make AYON more special and powerful as a pipeline management software.
This wiki is worth reading which tells how the idea of
pyblishstarted.
What is publishing · pyblish/pyblish Wiki · GitHub
Publish instances and Products
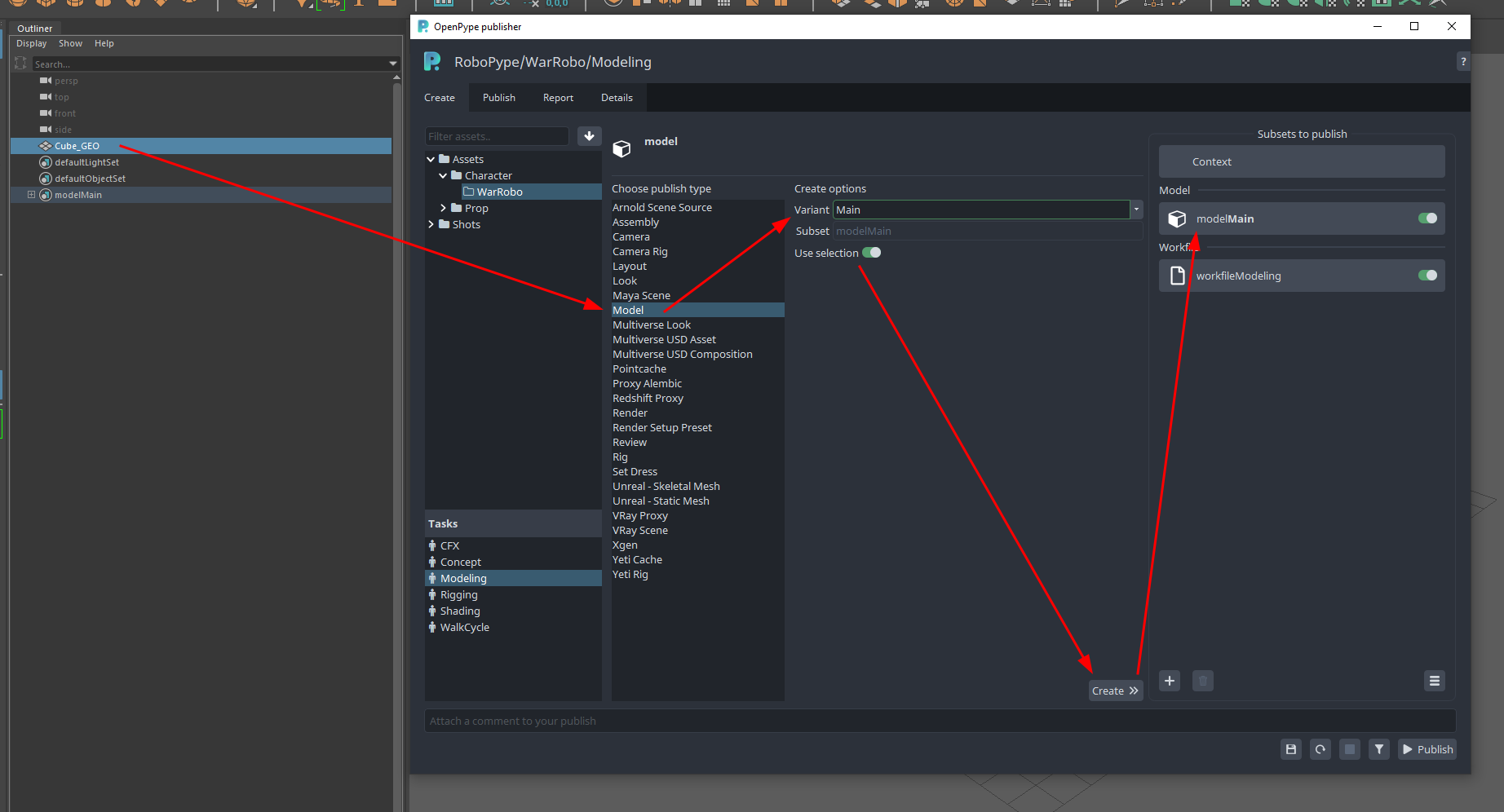
In order for AYON to publish your work, you would need to specify three things:
- your work, e.g. by selecting it
- the
product-typeof your work, e.g. aModel - the name that will be given to your published work (Variant name)
Then, AYON will use these inputs and create you a publish instance
So, each
publish instancemust be associated to only oneproduct-type
This is very helpful during validation process, as eachpublish instancewill run through different validations related to itsproduct-type.
Each publish instance contains a lot of data related to your work, e.g.
asset: Asset nametaskfamily:product-typevariantsubset: which in this case isfamily+variant
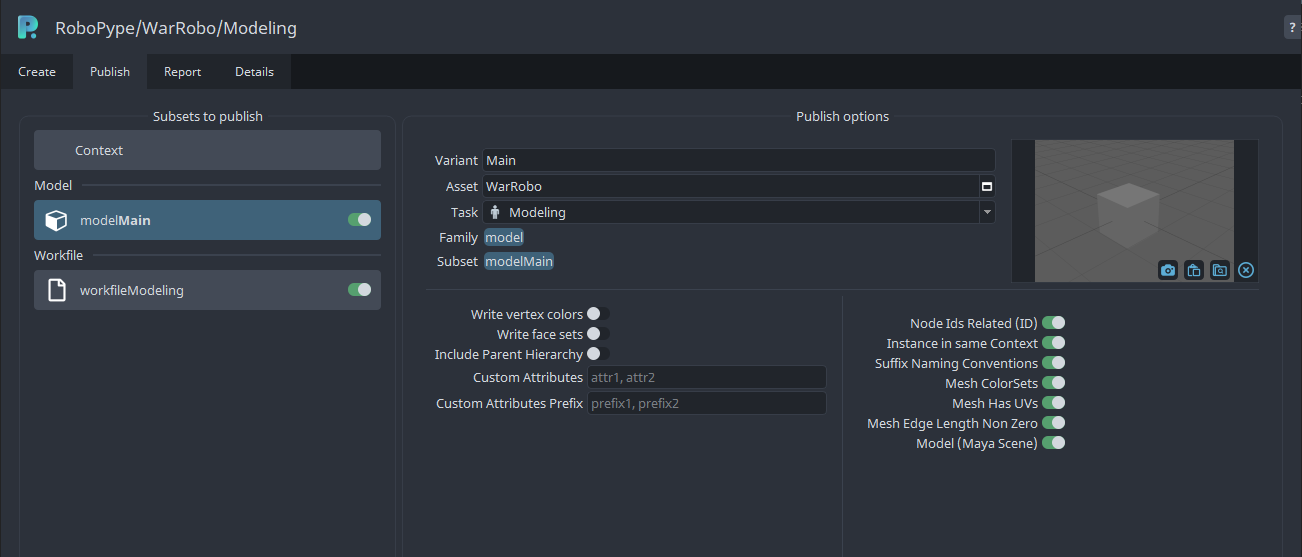
These data are saved as attributes on your work itself!
Recalling, you mark a group of data with special marks using a creator tool
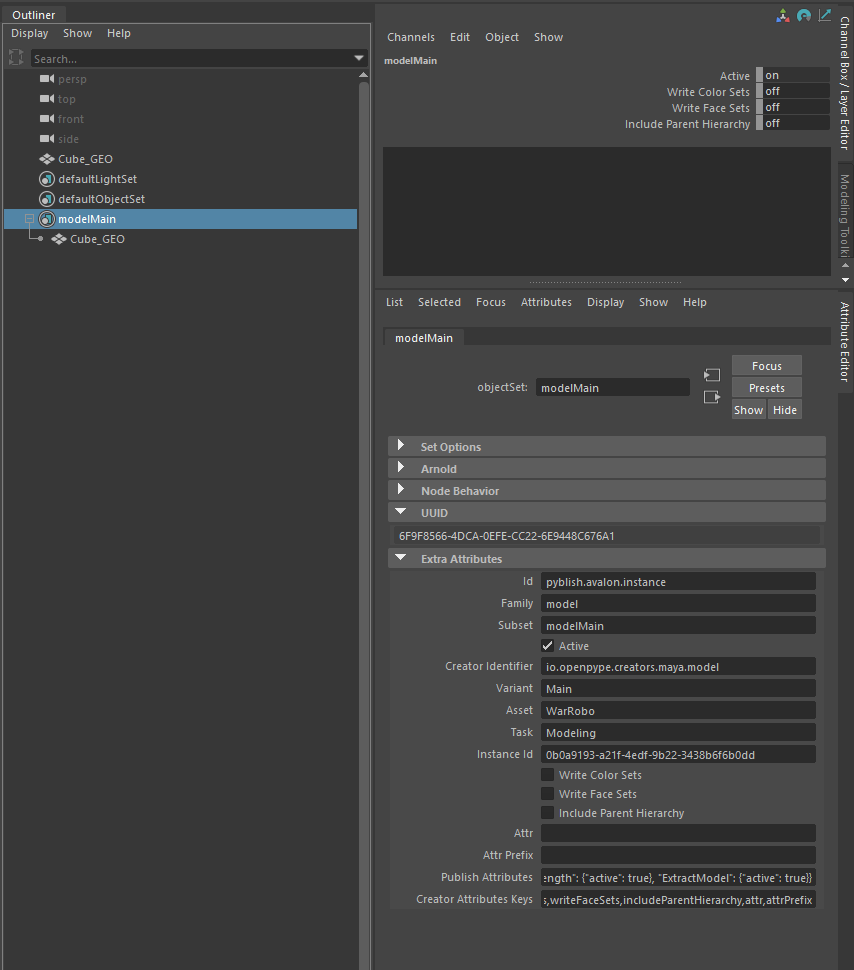
Product-Types Vs Representations
It’s super important to differentiate between product-types and representations when dealing with AYON/OpenPype, and in short:
- Product-Type: A product containing a specific type of information, e.g.
- pointcache/animation: a character animation output as cache of its geometry only (no controls, no bones; just geometry cached)
- camera: a single camera
- model: a static (clean) mesh adhering to studio rules like naming conventions, poly-flow, usually intended to be used as the clean geometry representing an asset.
- Representation: A file output for a product type.
- e.g. the data of pointcache product-type could be stored in any format supporting geometrical caches, like Alembic, USD, bgeo, etc.
- e.g. the data of camera product-type could be stored in any formatting supporting a single animated camera, e.g. Alembic, Maya scene, USD, etc.
Note how representation is just a different file format for the same product type - as such, a single product type could have multiple representations which should technically (for as far as the file formats allow) contain all the data of that product-type.
As such, another example (that might currently not exist) could be:
- A sketetal animation (with blendshapes) product type could be stored in multiple representations that support that, e.g. FBX supports skeletal animation, USD supports skeletal animations, GLTF supports skeletal animation.
I had a misconception when I was thinking of implementing FBX product type, which didn’t make sense because FBX can be a representation of various product types such as (
rigs,geometry,(basic) materials, and eventextures)
Then, I learnt that my implementation was actually ageometryproduct-type which would be represented as.fbxthen the whole thing turned into anUnreal Static Meshproduct-type.Find the full story here Unreal Static Mesh PR
Also, Here are some visual examples from Houdini:
example 1: Same product-types, different representations
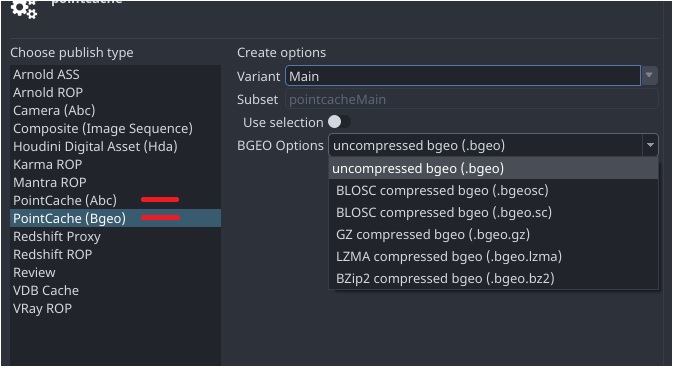
pointcacheproduct-type in Houdini has two representationsalembicandBgeo,
Each has its own ROP export node, so they are implemented as two different product types exporting the same data.product-types Alembic Bgeo 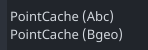
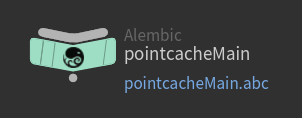
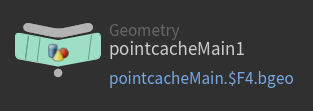
example 2: Different product-types, same representation.
- Both
pointcachesandcamerascan have the same representation *e.g. saved as.abc
However they are two distinctiveproduct-types, each have their own validations!product-types Alembic Pointcaches Alembic Cameras
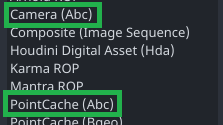

example 3: Same representation, different export options.
This has nothing to do with the
product-type
In some cases a representation can support different extensions, e.g.
USDsupports.usd,.usdcand.usda
Another example:
Bgeorepresentation in Houdini has many export options, but they are still the same representation
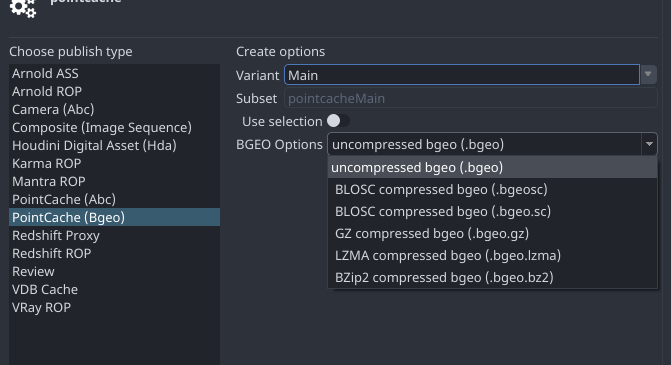
Here’s a proof, where I can swap asset version represented by different bgeo export options without any issues!
Context Vs Instances
Each DCC session/workfile has a pyblish context , each publish product is a pyblish instance
Each context denotes ( workfile path, project name, asset name, task name) and many more.
Each instance denotes a particular product-type.
from openpype.pipeline import registered_host
from openpype.pipeline.create import CreateContext
host = registered_host()
context = CreateContext(host)
print(
"Project '{}', Asset '{}'"
.format(
context.project_name, context.get_current_asset_name()
)
)
for instance in context.instances:
print("Instance: {}".format(instance.name))
# you can edit instances here
# if some_condition:
# instance.data[key] = value
pass
# To save change to context and instances
# context.save_changes()
Publish plugins can be configured to work at different levels i.e. context level and instance level
for example:
-
A validator to check some data of a particular product type, then this validator must inherit
pyblish.api.InstancePluginand product-type keyword should be specified, example Houdini Alembic product type validator -
A collector that collects data regarding the DCC session itself then you should use
pyblish.api.ContextPlugin, example context plugin: collect instances
Create
Creates a group or export/write node for the selected objects if desired
In Maya : it creates a Set
In Houdini : it creates a ROP node
In Nuke : it creates a Write node
It’s not saved as instance of a class however it’s just a group or a node that marked with some extra parameters
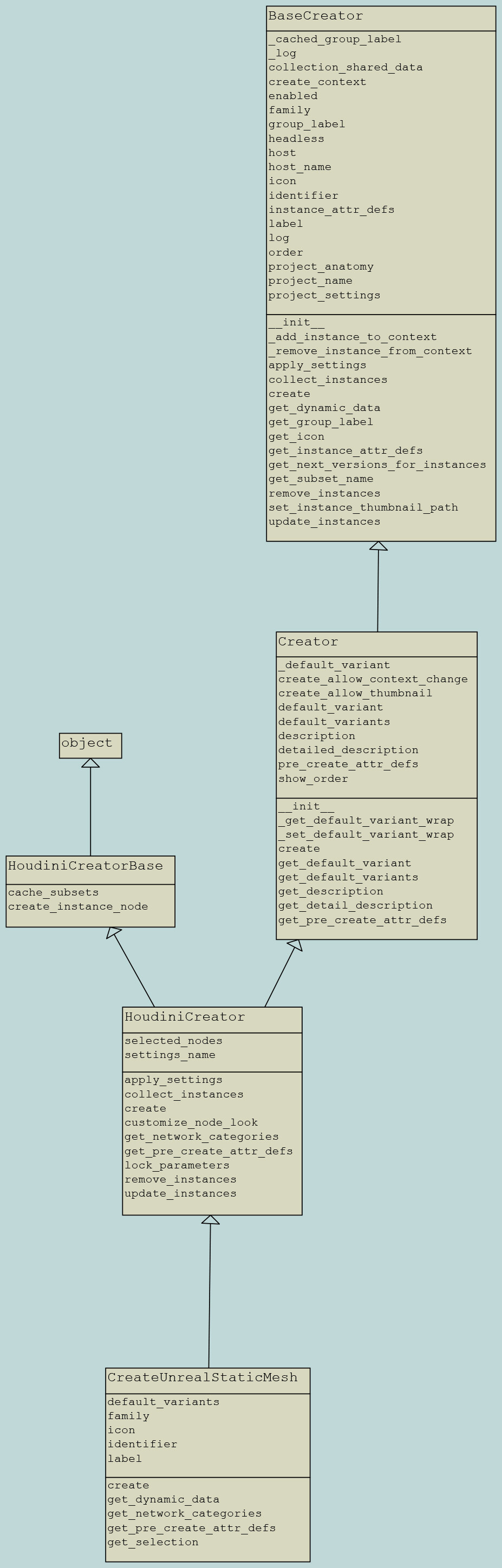
Creator class structure
Toke Stuart : To generate a new product type (family), you’d need to implement a creator for the new product type (family). If you follow the structure of the other creators, the new product type (family) instance should get picked up when publishing.
In Houdini
it’s required to inherit plugin.HoudiniCreator
- Class Attributes
identifierlabelfamilyicondefault_variant(optional)default_variants(optional)
- Class Methods
create- set node type
- create instance
- get parms
- set parms
- Lock parameters if needed
get_pre_create_attr_defs(optional)get_network_categories(optional, Houdini specific)get_dynamic_data(optional)
In Maya
it’s required to inherit plugin.MayaCreator
in many cases you would rely on MayaCreator.create()
so, you would only need to set class attributes
- Class Attributes
identifierlabelfamilyicondefault_variant(optional)default_variants(optional)
- Class Methods
get_pre_create_attr_defs(optional)get_dynamic_data(optional)
get_pre_create_attr_defs
Add settings for publish node
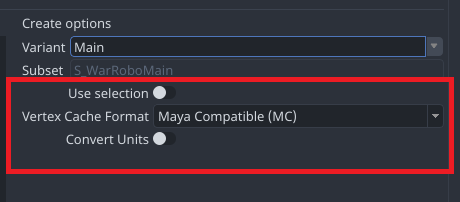
get_dynamic_data
You’d need in some cases to have a subset name template instead of the default product-type subset name,
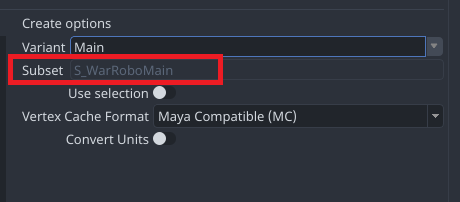
It’s a two step process
- Implement
get_dynamic_data - update Settings
-
In OpenPype
project_settings/global/tools/creator/subset_name_profiles
-
In AYON
Studio settings/ Core/Tools/Creator/Product name profiles
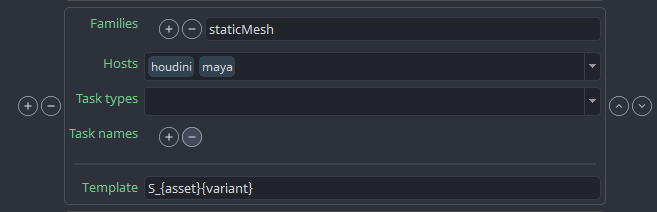
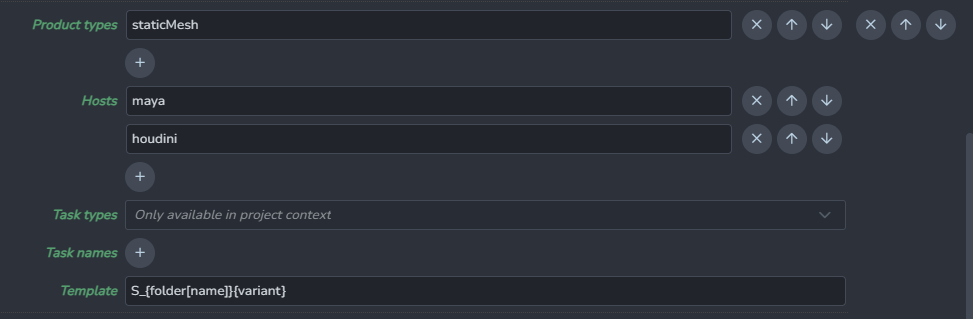
Project Settings
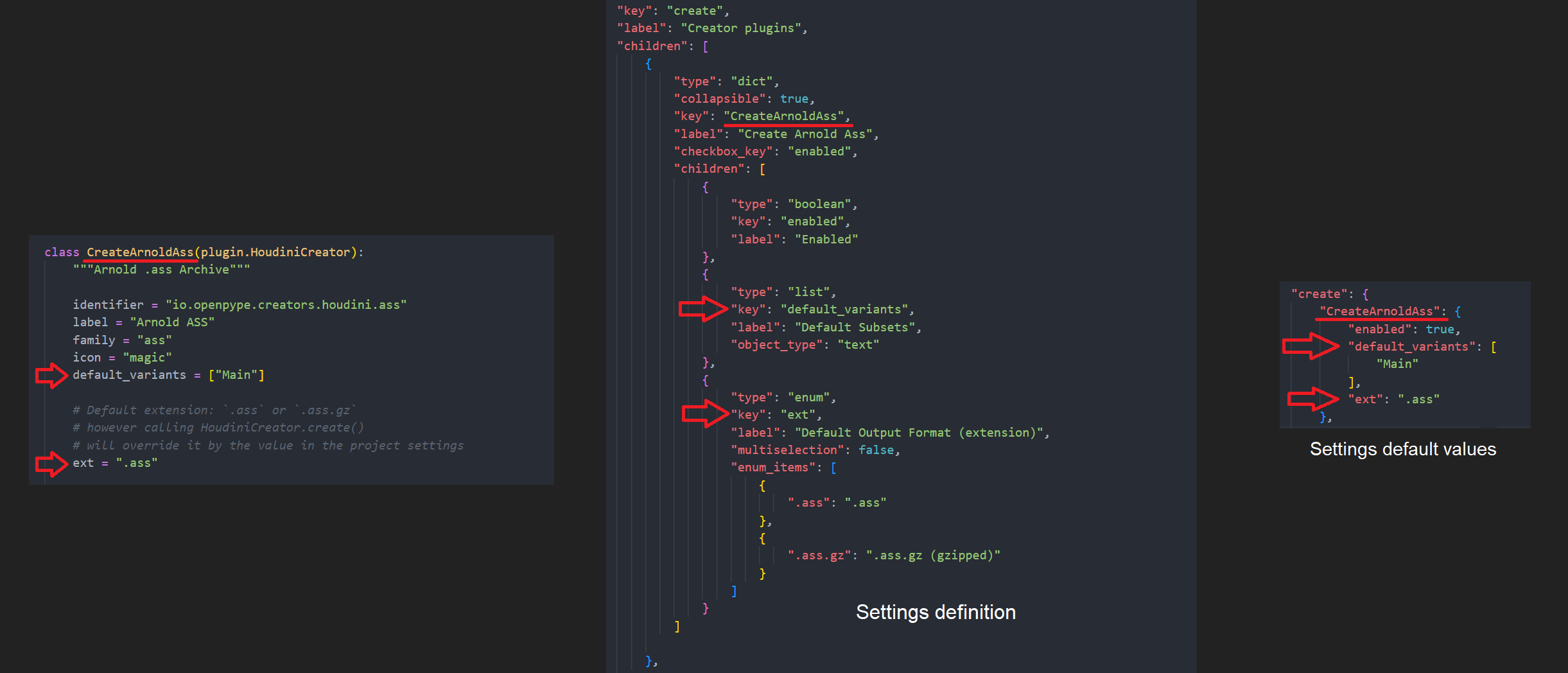
Respective creator’s settings are fetched and applied to creator class automatically.
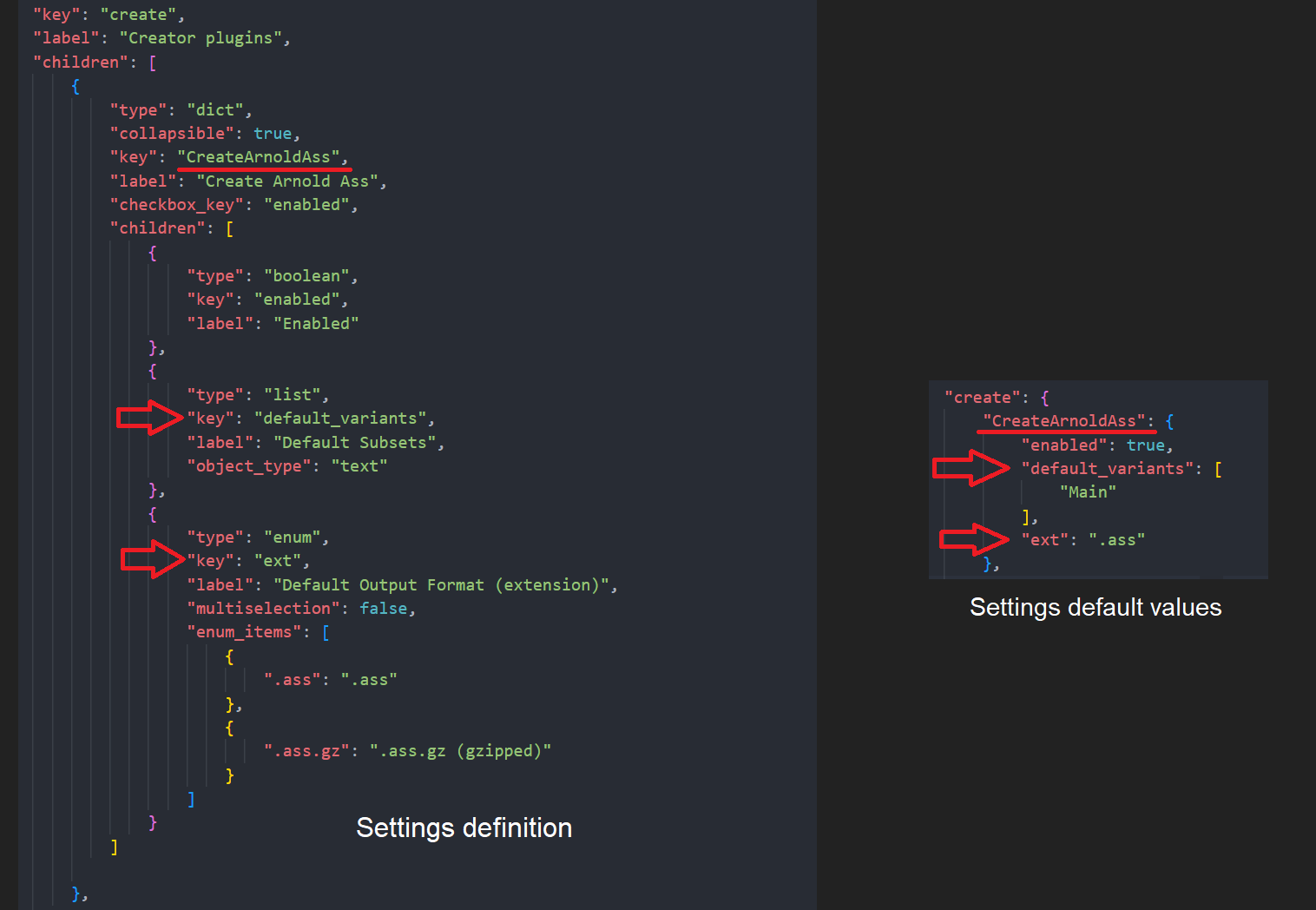
for example: Houdini CreateArnoldAss
ext , default_variants class attributes will be overridden by their values in settings automatically.
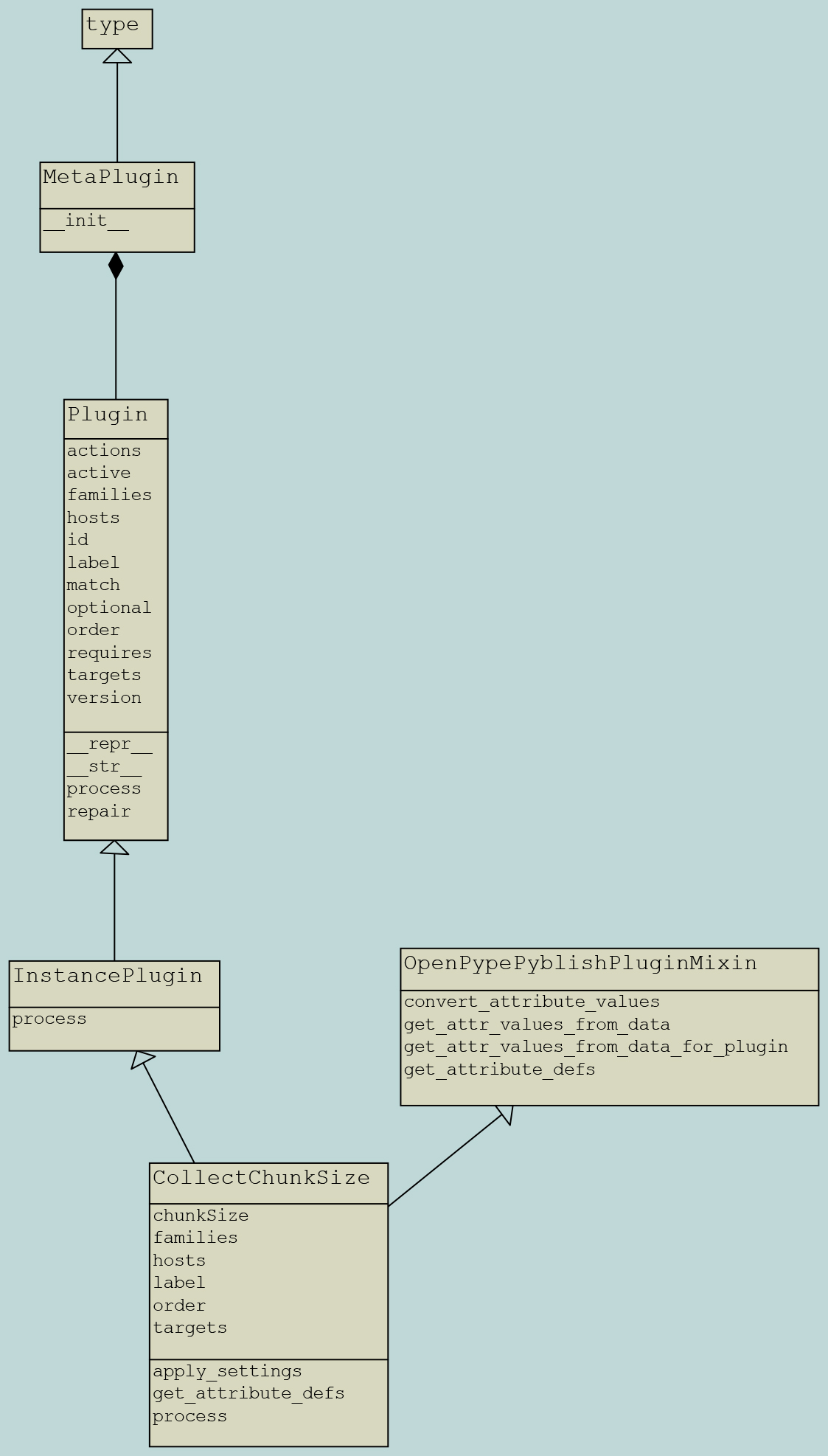
Collect
Collectors act as a pre process for the validation stage.
It is used mainly to update instance.data
Collector class structure
It’s required to inherit pyblish.api.InstancePlugin or pyblish.api.ContextPlugin
- Class Attributes
hostsfamilieslabelorderenable(optional)
- Class Methods
processget_attribute_defs(optional, it is associated withOpenPypePyblishPluginMixinorOptionalPyblishPluginMixin)
Attribute Defs
It’s similar to get_pre_create_attr_defs which adds user accessible attributes in publisher UI.
it’s done by OpenPypePyblishPluginMixin or OptionalPyblishPluginMixin secondary inheritance
It requires to call self.get_attr_values_from_data in process to get these attributes values
Enable and disable Collectors
The minimal setup is to add enable class attribute and "enable" key in the collector’s respective settings, Example: Search OP repo for CleanUpFarm
It’s possible to make collectors optional, Check Optional Validators
Collector Project Settings
Collector class attributes will be overridden automatically by their respective values in the collector’s settings.
To get settings of other plugins inside your collector, Jump to Get Settings
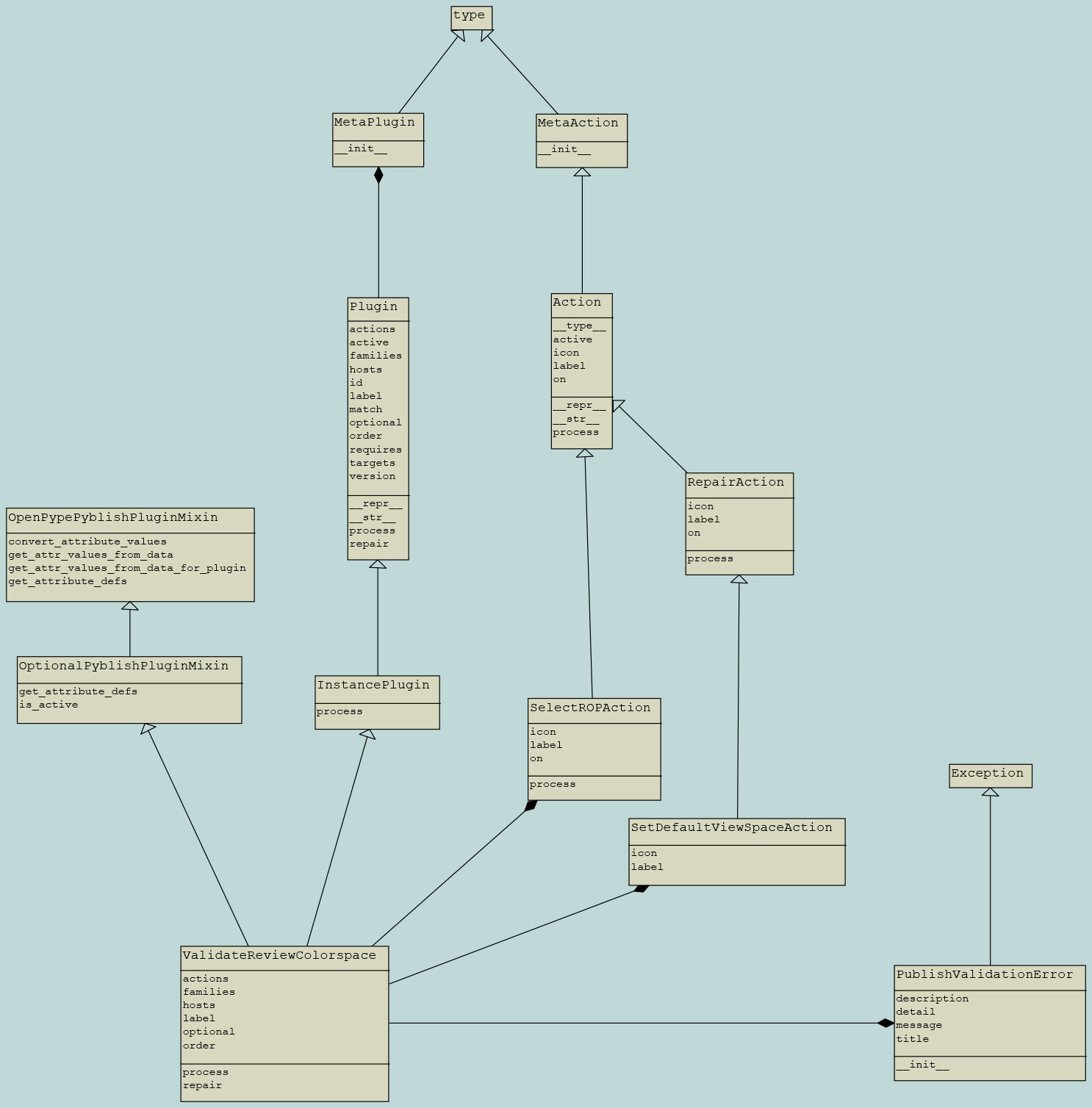
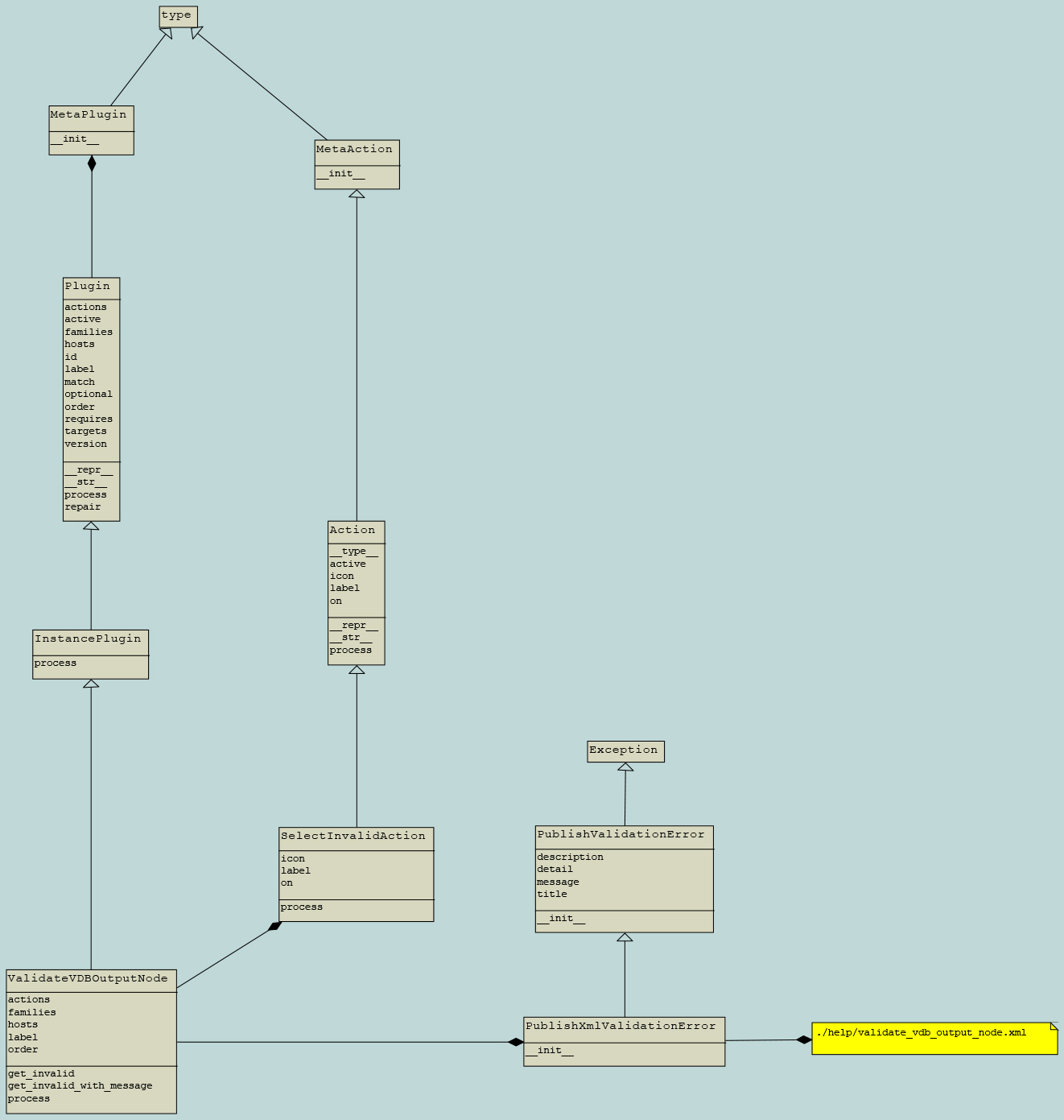
Validate
Validators are used to verify the work of artists,
by running some checks which automates the approval process.
Validator class structure
It’s required to inherit pyblish.api.InstancePlugin or pyblish.api.ContextPlugin
- Class Attributes
hostsfamilieslabeloptional(optional)order(optional)actions(optional)
- Class Methods
processget_invalid(optional, it is associated withSelectInvalidAction)repair(optional, it is associated withRepairAction)
get_invalidshould returnNoneif no problems
Otherwise, it should return the node associated with the problem
processmakes use ofget_invalid
Validation Error Types
PublishValidationError
A basic error report display.
Commonly used arguments message and title
PublishXmlValidationError
An advanced error report display which loads an xml file
Commonly used arguments
pluginwhich can be passed asselfmessagewhich is the same asPublishValidationErrorformatting_datawhich is a dictionary of data that map to curly brackets variables in xml
xmlfile must saved inpublish/helpdirectory and it must have the same name as the validator file name (just replace.pywith.xml)
Optional Validators
It’s done by OptionalPyblishPluginMixin secondary inheritance
it requires adding optional class attribute and add new project settings
for your validator.
you can use "template_data" which offers 3 keys ( "enabled" , "optional" , "active" )
...
"template_data"[
{
"key": "Validator class name",
"label": "Validator Label"
},
...
Alternatively, you can use the minimal setup like Enable and disable Collectors
Use existing actions
Implemented actions can be found in {host}/api/action.py
you can use them by importing them to your script
e.g.
from openpype.hosts.houdini.api.action import (
SelectInvalidAction,
SelectROPAction,
)
Create new Actions
Each validation can have a single repair action which calls repair method
to create a repair action you only make a class that inherits RepairAction class
then implement your action in repair method
Also, you can create as many actions as you want in {host}/api/action.py
follow the structure of other actions.
Validator Project Settings
Validator class attributes will be overridden automatically by their respective values in the validator’s settings.
To get settings of other plugins inside your validator, Jump to Get Settings
Extract
Extractors are used to generate output and update representation dictionary
Extract class structure
It’s required to inherit publish.Extractor
- Class Attributes
hostsfamilieslabelorder
- Class Methods
process
Extract Logic
- get rop node
- render rop
- get required data
- update instance data
About Representations
Requires:
instance.data['representations'] - must be a list and each member
must be a dictionary with following data:
'files': list of filenames for sequence, string for single file.
Only the filename is allowed, without the folder path.
'stagingDir': "path/to/folder/with/files"
'name': representation name (usually the same as extension)
'ext': file extension
optional data
"frameStart"
"frameEnd"
'fps'
"data": additional metadata for each representation.
Optional extractors
Similar to Optional Validators
Extractor Project Settings
Extractor class attributes will be overridden automatically by their respective values in the extractor’s settings.
To get settings of other plugins inside your extractor, Jump to Get Settings
Integrate (automated)
Integrate process is handled by
IntegrateAssetinopenpype/plugins/publish/integrate.py
It moves exported/rendered files to their publish path and do some automations that you don’t have to worry about.
Integrate requires:
- Registering new families in
integrate.py - Making sure that
instance.data['representations']is correct
Load
Which adds a load command for product types
Load class structure:
It’s required to inherit load.LoaderPlugin
- Class Attributes
labelfamiliesrepresentationsordericoncolor
- Class Methods
loadupdateremoveswitch
Load logic
get_file_pathget necessary datacreate_load_node_tree- return
containerised_nodes(it does some automations that you don’t have to worry about) - It moves created nodes to the
AVALON_CONTAINERSsubnetwork - Add extra parameters
You can customize loading by editing
create_load_node_tree
where you can add more nodes or attributes.
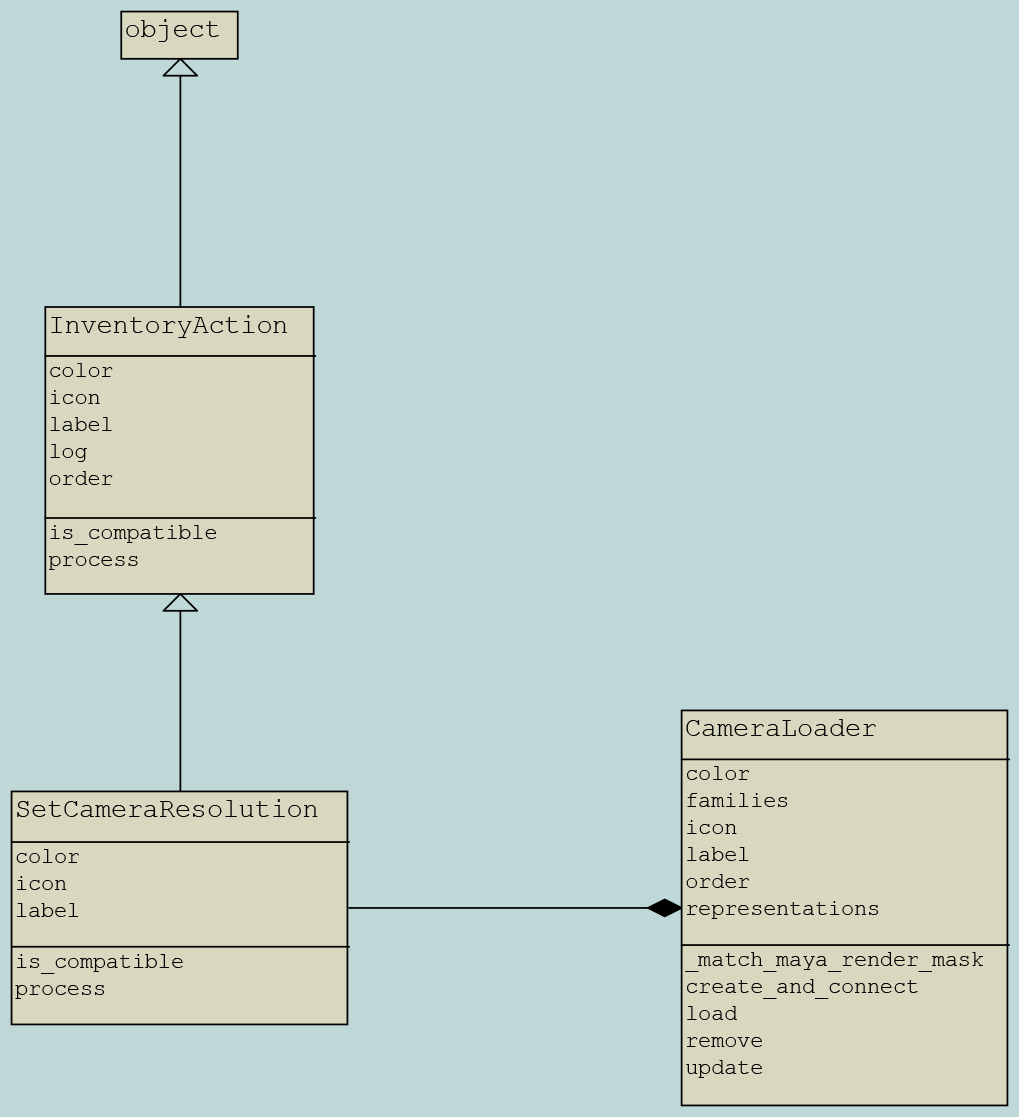
Inventory Actions
They add actions in Manage (Inventory) for users to perform some actions on loaded assets.
Inventory Action class structure
It’s required to inherit InventoryAction
- Class Attributes
labeliconcolororder
- Class Methods
processis_compatible(optional)
is_compatible
it can associate an inventory action to a particular loader
Attachments
Code Examples
These examples are from Houdini.
- creator: create_unreal_staticmesh.py
- collector: collect_chunk_size.py
- validator example 1: validate_review_colorspace.py
- validator example 2: validate_vdb_output_node.py
- extractor: extract_fbx.py
- loader: load_fbx.py
- Inventory Action: set_camera_resolution.py
UML Diagrams
Made with pynsource
| Creator | Collector | Validator example 1 | Validator example 2 |
|---|---|---|---|
| Extractor | Loader | Inventory Action |
|---|---|---|


Further Reading
Order
Order is an int value that defines the order publish plugins are called
"""Common order values. """
import pyblish.api
from openpype.pipeline.publish import ValidateContentsOrder
# Collector
order = pyblish.api.CollectorOrder
print(order) # equals 0
# Validator
order = pyblish.api.ValidatorOrder
print(order) # equals 1
order = ValidateContentsOrder + 0.1
print(order) # equals 1.2
# Extractor
order = pyblish.api.ExtractorOrder
print(order) # equals 2
# Integrator
order = pyblish.api.IntegratorOrder
print(order) # equals 3
Toke Stuart: I think one of the design flaws of Pyblish is its use of
orderfor scheduling plugins. The amount of plugins can quickly get complicated to a point where its hard to track dependencies between plugins.
Working with Settings
Get Settings
# Run in OP/Ayon Launcher console
from openpype.settings import get_project_settings
project_name = "RnD"
project_settings = get_project_settings(project_name)
print(project_settings["maya"]["publish"]["ValidateMayaUnits"])
# Run inside any host
import os
from openpype.settings import get_current_project_settings
from openpype.pipeline.context_tools import get_current_host_name
project_settings = get_current_project_settings()
print(project_settings["houdini"]["publish"]["ValidateWorkfilePaths"])
host_name = get_current_host_name()
print(project_settings[host_name]["publish"]["ValidateWorkfilePaths"])
# Publish plugins get settings by implementing apply_settings method
# This is only required if you want to get settings of another publish plugin
# for example I want to get 'CreateUnrealStaticMesh' settings inside 'ValidateUnrealStaticMeshName' plugin
@classmethod
def apply_settings(cls, project_settings, system_settings):
settings = (
project_settings["houdini"]["create"]["CreateUnrealStaticMesh"]
)
cls.collision_prefixes = settings["collision_prefixes"]
cls.static_mesh_prefix = settings["static_mesh_prefix"]
Add new Settings
First of all, settings are static (they don’t change unless you do that manually)
It’s a two step process
- Update Schemas/Settings
- Update Settings default values
Attention: If you do settings changes in OpenPype, also do the change in AYON addons settings.
Always Match Settings.
[OpenPype]
Update Schemas
Openpype Settings Schema Example File: schema_houdini_create.json
In OpenPype, there two ways :
- Settings with custom keys
- Settings with template keys
Custom keys
{
"type": "dict",
"collapsible": true,
"key": "CreateArnoldAss",
"label": "Create Arnold Ass",
"checkbox_key": "enabled",
"children": [
{
"type": "boolean",
"key": "enabled",
"label": "Enabled"
},
{
"type": "list",
"key": "default_variants",
"label": "Default Variants",
"object_type": "text"
},
{
"type": "enum",
"key": "ext",
"label": "Default Output Format (extension)",
"multiselection": false,
"enum_items": [
{
".ass": ".ass"
},
{
".ass.gz": ".ass.gz (gzipped)"
}
]
}
]
},
Settings Template
Notice you won’t find
CreateArnoldAssin the list"template_data"because it was already defined.
{
"type": "schema_template",
"name": "template_create_plugin",
"template_data": [
{
"key": "CreateAlembicCamera",
"label": "Create Alembic Camera"
},
...
}
Update settings default values
Openpype Default Settings Values Example File: houdini.json
Each key previously added in the schema should have a matched value in defaults.
for example check settings related to these two "CreateArnoldAss" and "CreateRedshiftROP" in the above example file.
[AYON]
AYON Settings Example File: publish_plugins.py
Update Schemas Equivalent
Currently, it’s done by editing the corresponding AYON settings file in server_addon
The above example file is the corresponding AYON Houdini settings file
where we add classes that inherit BaseSettingsModel
Update settings default values Equivalent
by scrolling a little bit down and adding a new dictionary item