I just recently discovered what in my opinion is a big limitation and a design flaw on the OP/Ayon philosophy (just for the sake of discussion I’m going to try just talk in Ayon terms although it’s the same limitation in OP) of enforcing products to have a unique name under a publish context and I wanted to raise this topic to discuss the reasons behind that and figure out what solutions we have to avoid user errors in the future and perhaps improve the current design.
This discussion started on Discord at this point Discord
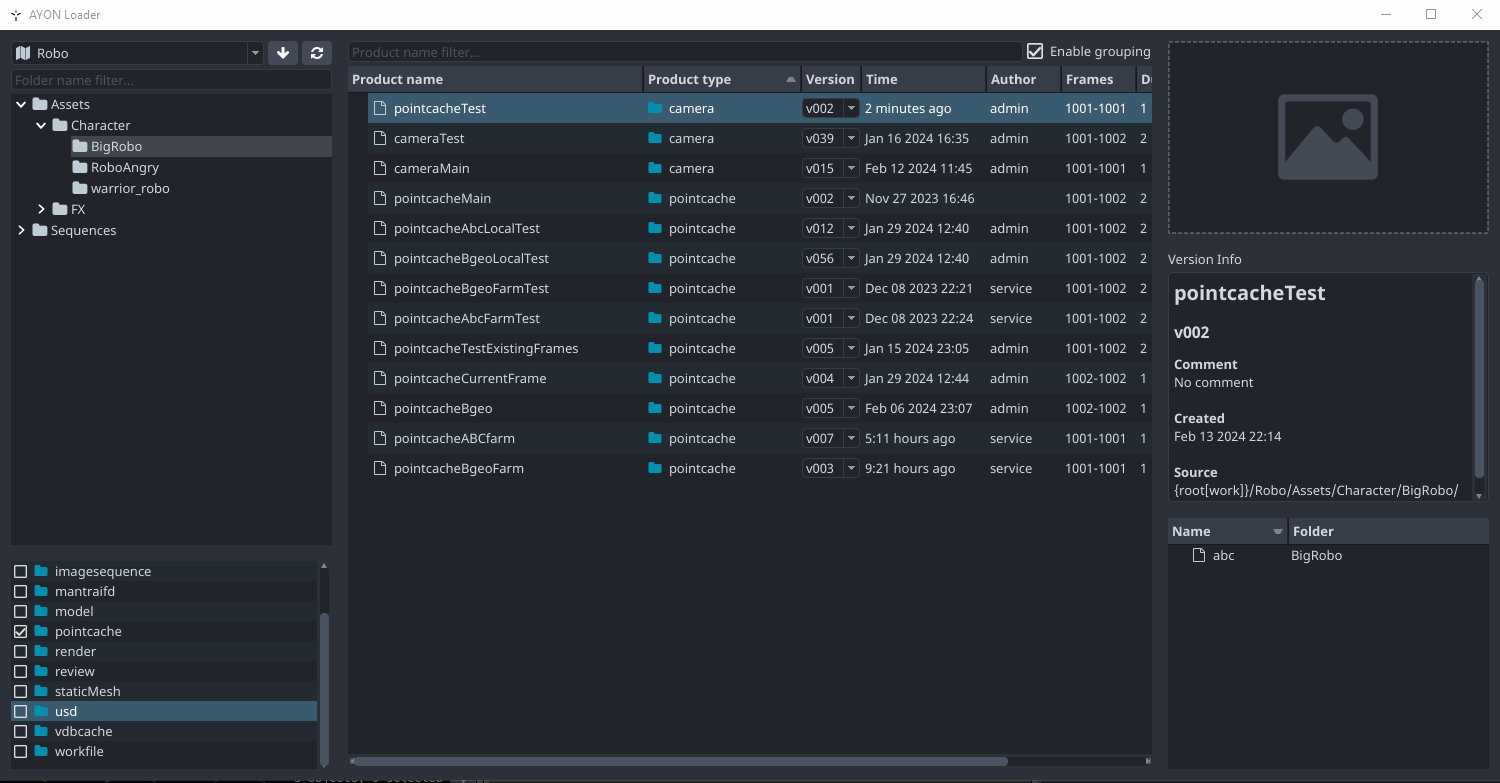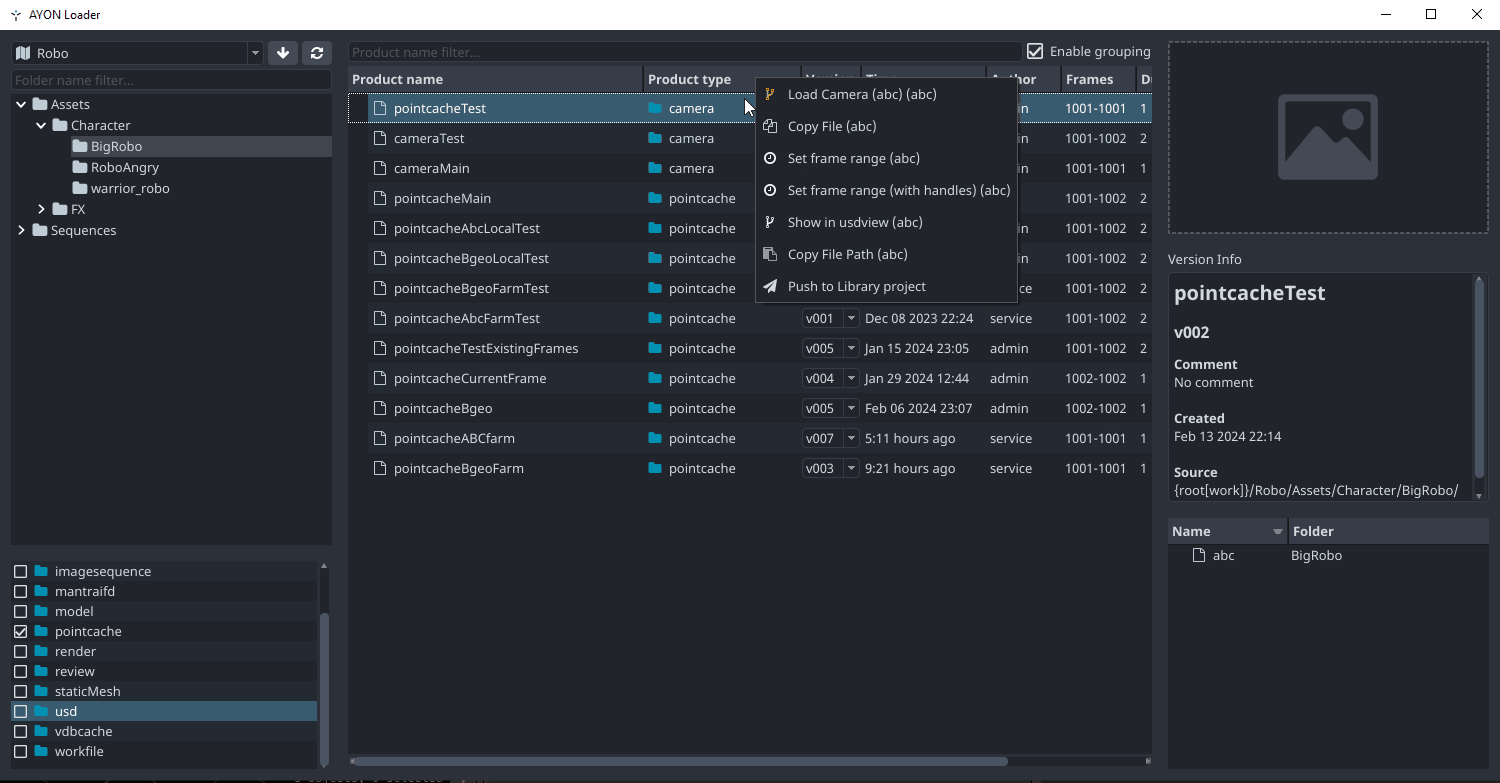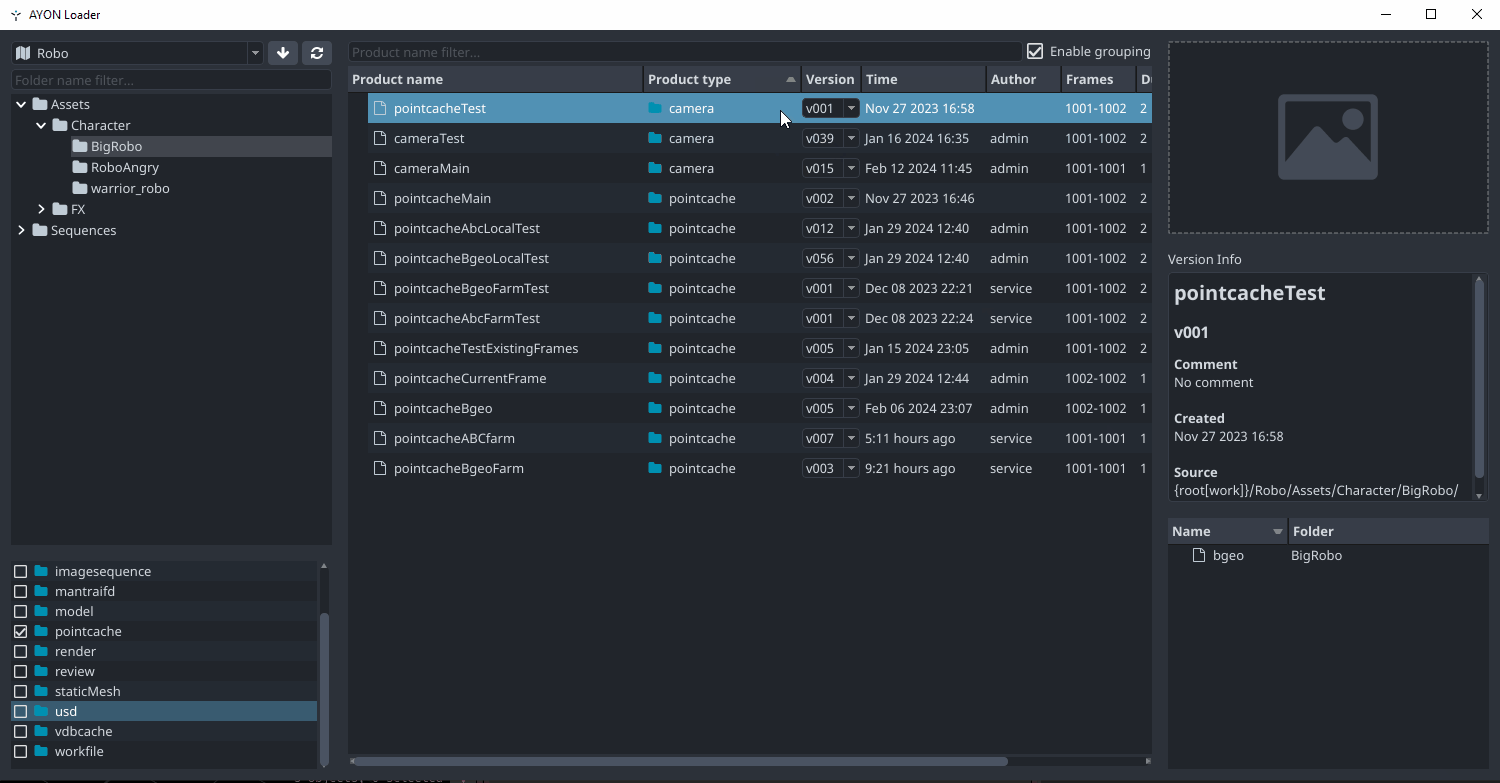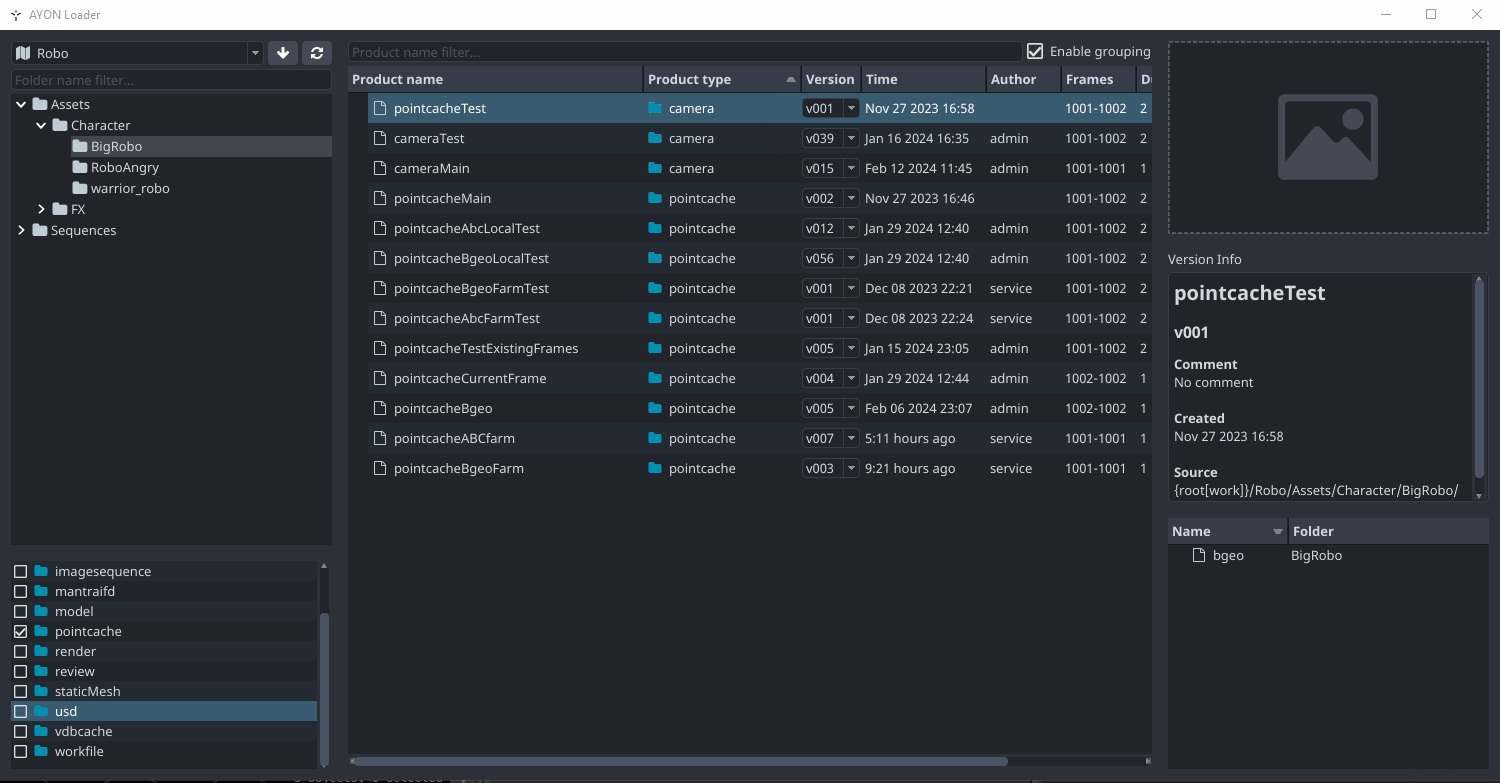
Currently we are able to choose the template tokens to use for each product type product names, the defaults are generally along the lines of {product[type]}{variant} but it’s great that we can tweak that to fit whatever studio workflow. However, if instead of using that template a pipeline like ours decides to use a more explicit workflow were artists name exactly how they want their product names and change it to just be {variant}, this shows the limitation that if an artist publishes two different product types using the same name, the system bugs out and ingests that second type under the same DB entry even though they are both integrated in two individual paths.
Real production example when doing this in OpenPype (replacing some of the names by tokens just for security purposes):
-
exrrepresentation of arenderproduct type:
/proj/<proj_name>/shots/410/031/<subset_name>/publish/render/<product_name>/v001/exr/<product_name>_v001.####.exr -
nukerepresentation of aworkfileproduct type:
/proj/<proj_name>/shots/410/031/<subset_name>/publish/workfile/<product_name>/v001/nuke/<product_name>_v001.nk
Both were written to individual file paths but they were treated as a single entity in MongoDB due to this code https://github.com/ynput/OpenPype/blob/aecbfa7352d42937bef5ff8929b46ab5be650eb3/openpype/plugins/publish/integrate.py#L412 only getting subsets by name and not validating whether the type being ingested is different than the retrieved subset. This specific use case would be easily fixed by just adding something like this:
if existing_subset_doc["data"]["family"] != family:
subset_doc = new_subset_document(
subset_name, family, asset_doc["_id"], data, subset_id
)
Just by this single example of a bad ingest, one could argue this is a bug in OP/Ayon since I’m able to break the system by simply tweaking the exposed template. So from this argument alone we should be adding extra validations to avoid an artist/admin doing such publish or enforcing the {product[type]} to be present ALWAYS on the product[name] of all publishes. However, while that would be a small improvement to the current system, I think both decisions would be wrong and limits the flexibility that Ayon should offer.
All the asset management systems that I have worked on don’t have a limitation on the data entries like what this is proposing. Shotgrid, ftrack and other proprietary AMS’s that I have seen in big studios like MPC and The Mill (all of them with proven years of industry expertise and backed up by a lot of artists) don’t have such strong opinions on enforcing uniqueness on the name of an entity. Even OpenAssetIO OpenAssetIO [beta]: Glossary doesn’t seem to be guided at all on doing that… see how all of the examples they provide as entity references contain a combination of fields and not something as basic as just a name!
The database entries already have the information of the {product[type]} or {task} as fields of that entry so having to add that information to the name itself is redundant and we shouldn’t have to enforce that for the names to be unique.
I also mentioned performance implications on my discussion in Discord since theoretically, a system where all product queries are bound to be queried by just the name is a much bigger query space than if you can filter out that space with other fields (i.e. type). I would need to dig deeper in the system to prove this but it would be interesting for someone from Ynput to do the following test:
Create 1000 random product names with different product types and compare the time to do the query of:
- Get product name “x”
- Get product name “x” with type “y”
So… what’s the idea behind this design and what benefits do you get from it? Why would we want to enforce this?