It has been discussed and mentioned several times that the current Houdini integration implementation does not meet many specifications.
For example:
It doesn’t support procedural publishing, it doesn’t make use of the existent tools like deadline tools which requires re-implementing them (re-inventing the wheel!)
So, let’s define the first principles of publishing and please correct me if I’m wrong:
Pyblish Concept
It’s based on injecting validation scripts between clicking the render button and the action of rendering
These validations should troubleshoots artist work.
The way Pyblish (technically) works is by adding meta data (special attributes) on top of the artist work (let’s call it publish instance), then Pyblish will be able to explore the scene file and grab these publish instances.
Finally, Pyblish will run the validation scripts and if things are good it will run the proper export command associated with each publish instance.
To adopt it in Openpype:
We introduced create , publish menu actions, they behave a little differently for each DCC
In Maya :
create should create a container with meta data (a set)
publish should find all containers (sets) , validate and export them one by one in alphabetical order by their subset name.
For DCCs like Maya it fits well because every thing is straight forward
- artists can create sets with the proper meta data themselves (or even using a quick script)
- artists can drag and drop new objects in that set to include them in that specific publish
- they will click
OpenPype > Publish, instead of selecting the set and clickingFile > Export Selection...
With DCCs like Houdini, There are always many ways to achieve everything due to its nodes system and procedural nature.
So, it’s quite limiting when trying to adopt Pyblish in Houdini in the way it’s adopted in Maya
And let’s not forget the post-publish Openpype/Ayon functions.
Houdini Publish instances
So, what a Houdini publish instance should be ?
Should it be a ROP node (as the current implementation) ?
or
Should it be an sop output node / rop node? that can be export by ROPs or TOPs ?
Output sop nodes can be amazing but we can’t use them for cameras for example !
| output SopNode | rop RopNode | fetch RopNode | wedge RopNode | subnet RopNode |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| rop SopNode | rop TopNode | fetch TopNode | wedge TopNode | subnet TopNode |
 |
 |
 |
 |
 |
Publish system
Note that publishing depends on how we define publish instances!
How the publishing in Houdini should work ?
Should a separate plugin (a publisher for example) grab all the publish instances and publish them one by one (the current implementation)?
or
Should each publish instance publish itself without invoking the publisher? like a series of nodes (render, publish)
or
Should both be supported ?
I need to point out that each publish instance has a pre-process → (validations) and post-process → (extract, integrate).
so, in order to use the vanilla houdini ROP nodes, we encapsulate it with a pre-process and post-process, we can achieve that by
| pre and post nodes | a single input/output wrapper node (subnet) |

Publishing to Farm
Let’s take deadline addon as an example,
Ayon has its own deadline addon where we sent two jobs, render job and publish job
For other DCCs that’s a fantastic feature.
but for Houdini, it looks like we are duplicating an existing features that already works well!
So, how would we reuse them ?
I think it would work if we could
- fake that the job was submitted from Ayon/Openpype (this happens when adding environment variables to your submittion)
- have a publish node
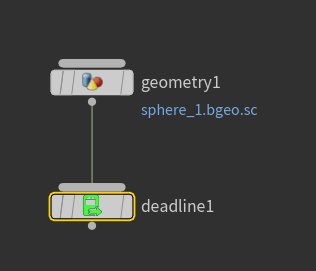
Here’s my a demo test:
|
Steps I made: 1. save a hip file on shared storage 2. add a sphere and a geo rop node 3. connect it to a deadline otl 4. submit a job |
 |
|
for the first glance it fails, but as soon as I added essential environment variables, it worked as it were submitted from Ayon/Openpype. (I used deadline monitor to add these vars, and I don't know how to do that from the deadline otl) |
|
|
here's a proof from the log that it worked the same as any job published from Ayon/Openpype you can find that `GlobalJobPreload` is triggered! |
|
| Note that this is my houdini deadline configuration! and no way houdini will run without running `GlobalJobPreload` |


The current implementation
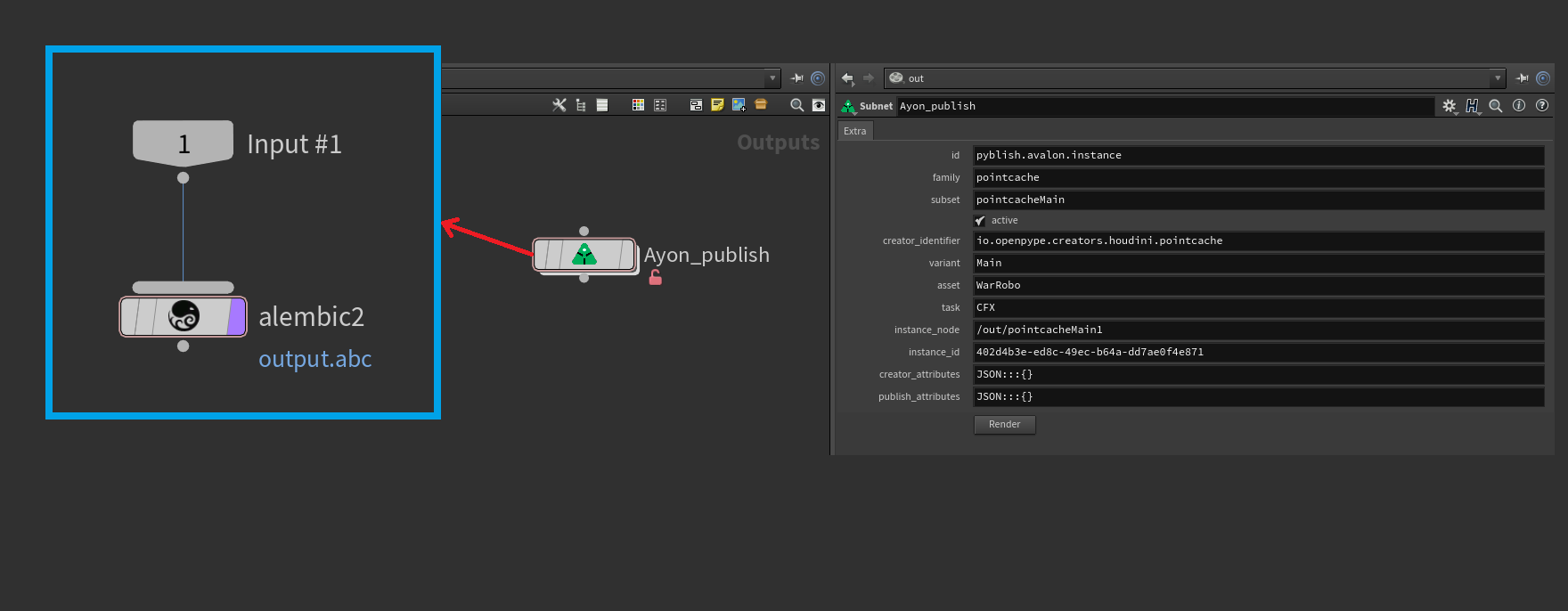
- Each Publish instance is a ROP node whose
instance.dataincludes- Frame Range
- Output Node
- Output File
- ROP specific parameters (e.g., path parameter in alembic ROPs)
- extra attributes
- id
- family (product-type)
- subset
- active
- creator_identifier
- variant
- asset
- task
- instance_node
- instance_id
- creator_attributes
- publish_attributes
- Publish System
- Publisher grab all ROP nodes
- Run validations and other things on publish
instance.data - Do some OpenPype/Ayon related operations