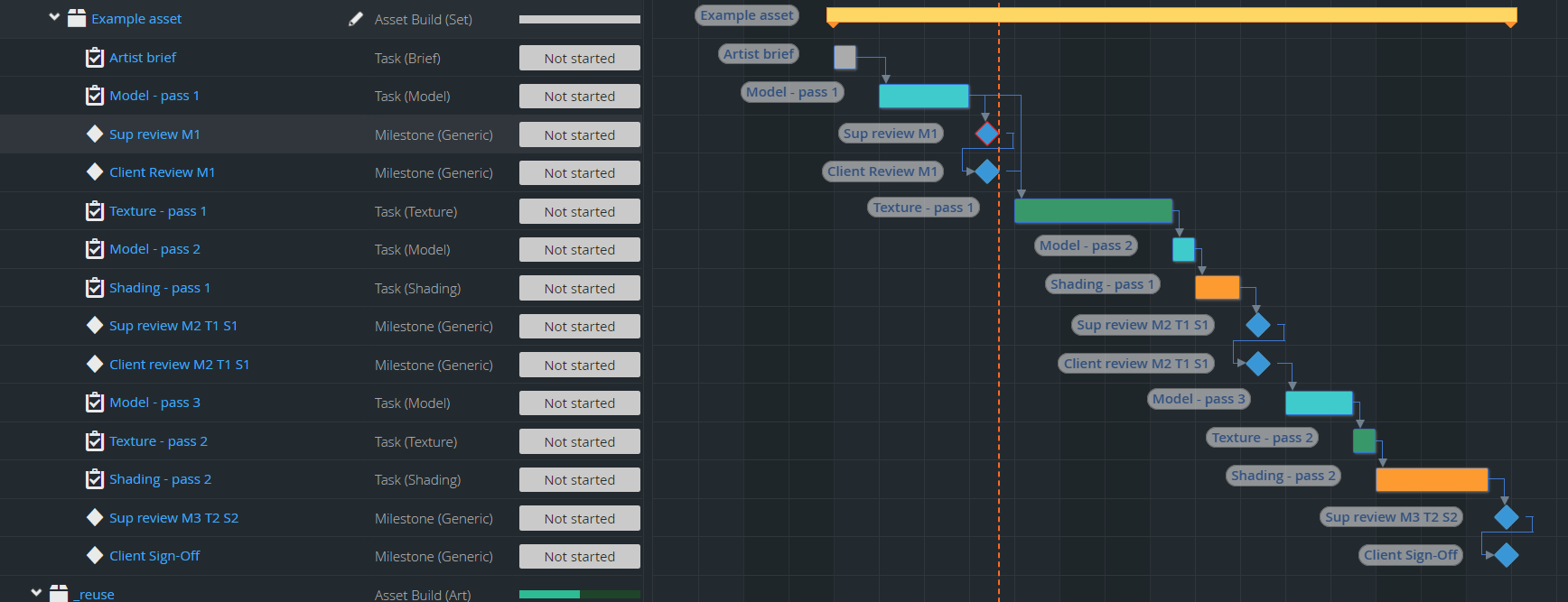
Bigger studios I’ve worked with use a ‘staged’ workflow for CG (short) movie creation. There are usually 3-4 stages, and at the end of each stage they put together and render out the full movie. In this way you can concentrate your efforts where it really matters in terms of visible quality, and you can involve the client in the decisions you make. We at Moonrock use this staged workflow as well.
So for example “room” asset in stage 1 is rendered out with roughly finished model with basic textures and temp materials, in stage 2 with final model, more refined textures and basic shaders, and in stage 3 it reaches proposed final textures and shaders. All the stage tasks for the same task type (eg. texturing) are usually assigned to the same artist.
So for “room” there are 3 texturing tasks (room texture s1, room texture s2, room texture s3) and the studios I know tracking these with separate tasks. And that makes sense as the timings, etc. are different, on the production management level they are really separate tasks. If I create separate tasks in FTrack, then I have to move the last workfile between the tasks in OP (there was a conversation earlier about this), but unfortunately it is not that simple. Besides the workfile there could be a lot of additional helper files in different folders which should be moved as well. Maybe they can be described with some templates, but it would be much simpler and robust to be able to use the same OpenPype task (workarea) for these staged tasks.
Example from FTrack:
we were discussing something similar - ability to sync workfile between published and current in Workfile tools. So user could see in workfiles even published workfiles, select it context and hit “copy to work”(or whatever).
Continuing from Discord:
@tokejepsen, @antirotor In our usecase the problem is that it is not just the workfile which we want to move to the next task. For texturing there could be some collected pictures, brushes in some folders, for modeling there could be some sketches. For grooming with Yeti there are some Yeti workfiles besides the Maya workfile. The point is that in some cases the workfile itself is not enough to continue the work.
You can imagine this use case as this is the same task but we want to iterate on it in multiple times at separate points in time. But if it is just one task in the Project management, then we can’t separate these tasks in time, can’t track their statuses separately, can’t connect them to different milestones, etc.
Is it then a lack of publishable data?
If you could publish all the data you need for the next stage, would that not be safer than people modifying data that has already been approved at an earlier stage?
Yes, that is a valid point and that would be the ideal solution by the book.
But in practice it would be a hard to ask artists to collect all the files they used to create a specific publised workflie by hand and publish them as well (probably in standalone publisher). Besides there won’t be connection to the published workfile other than the close publish date.
Another practical example texture painting. Substance Painter (we use to create textures) workfiles are super huge, these could be easily reach hundreds of megabytes in size for one character for one version, so artists simply don’t publish these, just the exported textures with lookdev.
So in theory yes, a publish should include all files which represent a version, but in practice it is a really hard thing to do in naming convention based asset management system (like OP). So some practical shortcut would be ideal for users who are willing to risk using this shortcut.
So maybe if you could publish a workfile with a folder of resources? Similar to how looks work in Maya?
Yes, that could be also a solution. In this case I would generalize it, like having a setting where you can define a list of folders for each task type which would be published along with the workfile.
@BigRoy wrote on discord:
Or if the issue is solely related regarding a connection to a production tracking solution like Ftrack you could solve it in that connection module?
A single asset could have:
ftrack_linked_tasks = ["id1", "id2", "id3"]
ftrack_active_link = "id2"
I think it would perfectly solve the issue.
@BigRoy wrote: I’d love to also know how, from a UX standpoint, you would want to set what stage you’d be working for. What decides whether you are at stage1 or stage2 for the artist?
For an artist stage 1,2,3, mean pre-defined goals to achieve on the same asset, representing higher and higher quality. For all assets, shots, a stage’s deadline date is more or less the same. Reaching that date the movie is rendered out and decisions made which assets should get more attention.
You can imagine it as a formalized iteration mechanism which show all assets in the full rendered shot context at the end of each stage.
(I’ve also updated the first post to include an Ftrack screenshot, which shows more or less a real world example.)
If it’s based on task type then you can right now create new work template where you replace "task[name]" with "task[type]" and add filter to use the template in project_settings/global/tools/Workfiles/workfile_template_profiles. But I expect it is not type based?
Also if you don’t care that all workfiles are in same folder then you can just remove task[name] from directory template so you can see all workfiels from all tasks in workfiles tool.
I can imagine that task on asset would have something like a "group" same way like have "type" right now that could be used in templates. It should definetely not override "name" but the code should check if group of task is filled and if not then use task name instead. In that case you can use task[group] and task[name] in templates at the same time which gives more abilities when needed. For example directory template can have task[group] but filename can have task[name] so you can see workfiles from different task in workfiles tool but use different versioning for different task name.
In all cases the question is where and how to set the thing I’ve called “group”. I don’t think using ftrack links solve what is the source name (or does?) that should be used in templates. It can easily cause accidental change of the group value during production.
Yes, it is mostly based on task type, so your suggestion works, thanks a lot!
The only question for us, how to handle the exceptions where we want a unique workfile despite the task has the same type for the given asset. You suggested a “group” attribute, which works, but in our use case having a unique workfile for the same type is more the exception than the standard, so I suggest an reverse solution.
On the task there could be an altName (alternate name) string attribute, and we need a Task[altName_or_Type] token. It would use the value from altName attr if present, or the type attribute if not present.
For the reverse situations where the workfile is unique for each task, but occasionally need to group these (your suggestion) there could be a Task[altName_or_Name] token. It would use the altName attr value if present or the Name if not present.
With these two new tokens it would cover all use cases I think. Of course the altName attribute name is just an idea, it can be anything.
ps.:
During checking the Task[type] in naming conventions I think I discovered 2 bugs, I’ll create Issues for them.
We can use it as @iLLiCiTiT suggested for now ( Task[type] in folder naming convention ), handling exceptions as separate assets. However, it would be nice to have an elegant solution described above sometime in the future.