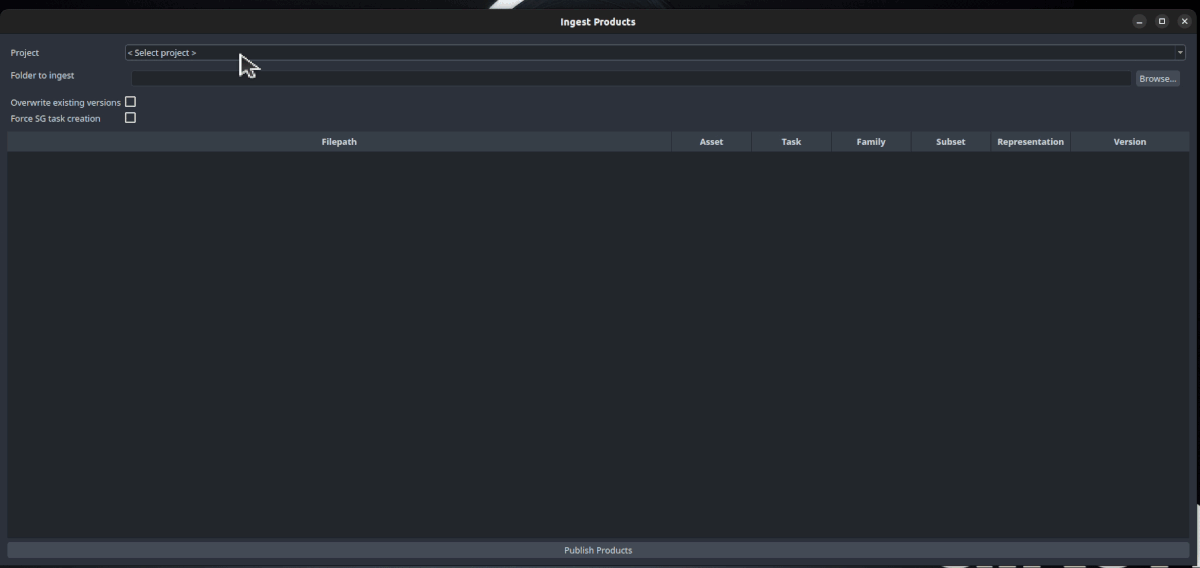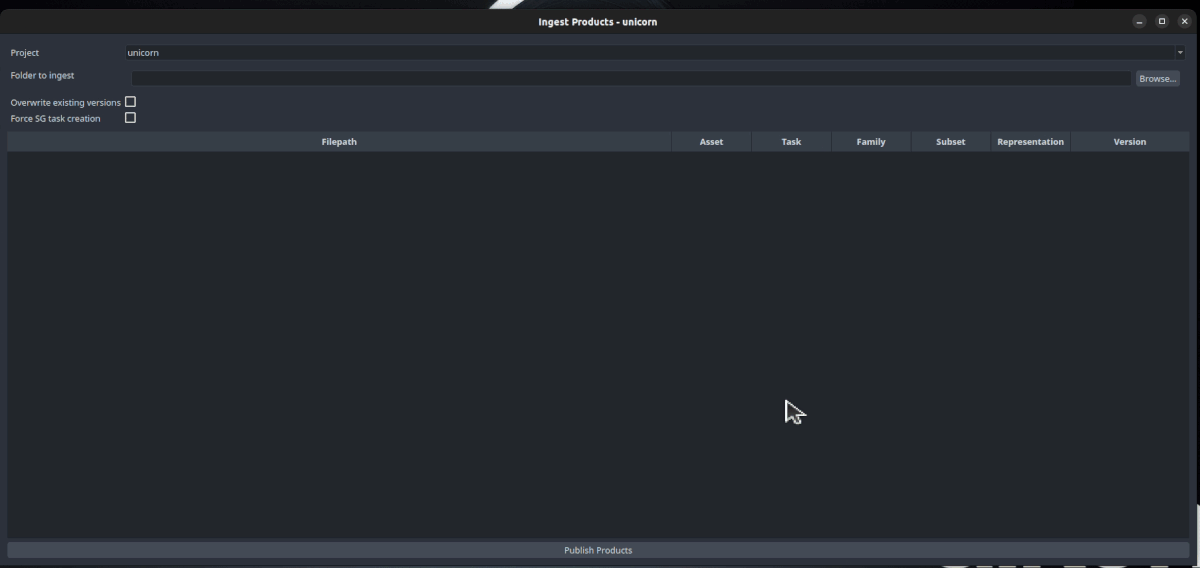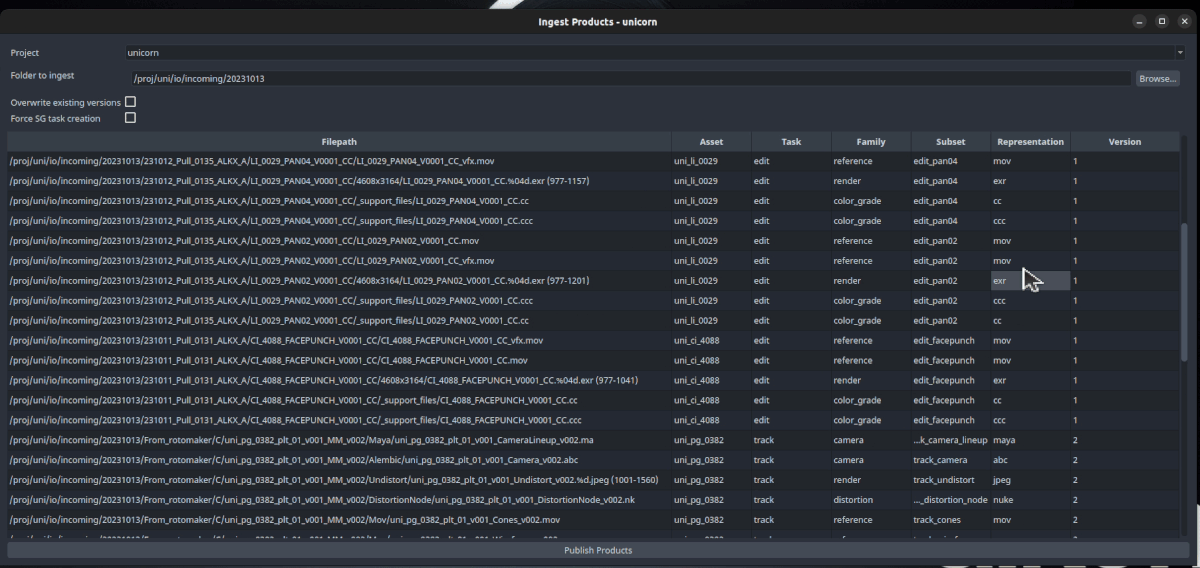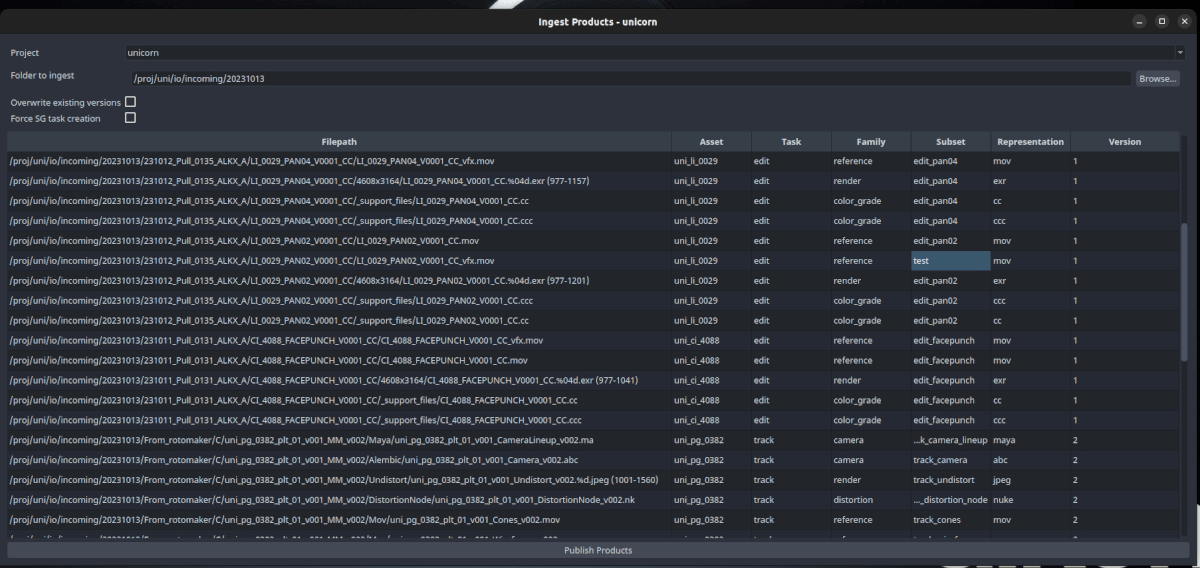
Here’s the code that I’m using right now for abstracting the OP publishes by submitting them to Deadline. Maybe this is a bit overkill for certain subset publishes that could probably go fast enough locally… but this has allowed me to write a very thin layer publisher in Houdini and I’m now writing a batch ingest tool that would use the same modules. It’s still very much WIP and I took some shortcuts in order to have something ready faster. I was planning on cleaning it further and create a draft PR in Github but for now some of this might help you and it might help me get some early feedback:
Publish version abstraction:
import os
import getpass
import json
from openpype.lib import Logger
from openpype.pipeline import legacy_io
from openpype.modules.deadline import constants as dl_constants
from openpype.modules.deadline.lib import submit
from openpype.modules.delivery.scripts import utils
logger = Logger.get_logger(__name__)
REVIEW_FAMILIES = {
"render"
}
PUBLISH_TO_SG_FAMILIES = {
"render"
}
def publish_version(
project_name,
asset_name,
task_name,
family_name,
subset_name,
expected_representations,
publish_data,
):
# TODO: write some logic that finds the main path from the list of
# representations
source_path = list(expected_representations.values())[0]
instance_data = {
"project": project_name,
"family": family_name,
"subset": subset_name,
"families": publish_data.get("families", []),
"asset": asset_name,
"task": task_name,
"comment": publish_data.get("comment", ""),
"source": source_path,
"overrideExistingFrame": False,
"useSequenceForReview": True,
"colorspace": publish_data.get("colorspace"),
"version": publish_data.get("version"),
"outputDir": os.path.dirname(source_path),
}
representations = utils.get_representations(
instance_data,
expected_representations,
add_review=family_name in REVIEW_FAMILIES,
publish_to_sg=family_name in PUBLISH_TO_SG_FAMILIES,
)
if not representations:
logger.error(
"No representations could be found on expected dictionary: %s",
expected_representations
)
return {}
if family_name in REVIEW_FAMILIES:
# inject colorspace data if we are generating a review
for rep in representations:
source_colorspace = publish_data.get("colorspace") or "scene_linear"
logger.debug(
"Setting colorspace '%s' to representation", source_colorspace
)
utils.set_representation_colorspace(
rep, project_name, colorspace=source_colorspace
)
instance_data["frameStartHandle"] = representations[0]["frameStart"]
instance_data["frameEndHandle"] = representations[0]["frameEnd"]
# add representation
instance_data["representations"] = representations
instances = [instance_data]
# Create farm job to run OP publish
metadata_path = utils.create_metadata_path(instance_data)
logger.info("Metadata path: %s", metadata_path)
publish_args = [
"--headless",
"publish",
'"{}"'.format(metadata_path),
"--targets",
"deadline",
"--targets",
"farm",
]
# Create dictionary of data specific to OP plugin for payload submit
plugin_data = {
"Arguments": " ".join(publish_args),
"Version": os.getenv("OPENPYPE_VERSION"),
"SingleFrameOnly": "True",
}
username = getpass.getuser()
# Submit job to Deadline
extra_env = {
"AVALON_PROJECT": project_name,
"AVALON_ASSET": asset_name,
"AVALON_TASK": task_name,
"OPENPYPE_USERNAME": username,
"AVALON_WORKDIR": os.path.dirname(source_path),
"OPENPYPE_PUBLISH_JOB": "1",
"OPENPYPE_RENDER_JOB": "0",
"OPENPYPE_REMOTE_JOB": "0",
"OPENPYPE_LOG_NO_COLORS": "1",
"OPENPYPE_SG_USER": username,
}
deadline_task_name = "Publish {} - {} - {} - {} - {}".format(
family_name,
subset_name,
task_name,
asset_name,
project_name
)
response = submit.payload_submit(
plugin="OpenPype",
plugin_data=plugin_data,
batch_name=publish_data.get("jobBatchName") or deadline_task_name,
task_name=deadline_task_name,
group=dl_constants.OP_GROUP,
extra_env=extra_env,
)
# publish job file
publish_job = {
"asset": instance_data["asset"],
"frameStart": instance_data["frameStartHandle"],
"frameEnd": instance_data["frameEndHandle"],
"source": instance_data["source"],
"user": getpass.getuser(),
"version": None, # this is workfile version
"comment": instance_data["comment"],
"job": {},
"session": legacy_io.Session.copy(),
"instances": instances,
"deadline_publish_job_id": response.get("_id")
}
logger.info("Writing json file: {}".format(metadata_path))
with open(metadata_path, "w") as f:
json.dump(publish_job, f, indent=4, sort_keys=True)
return response
The utils module that’s basically a rip off of other OP functions but I removed the instance object and other things so I was able to use them easier. There’s also this get_representations function that I wrote pretty quickly so I’m able to create the representations from just a dictionary of keys being the name of the representation and value a single path from the corresponding representation:
import clique
import re
import glob
import datetime
import getpass
import os
import requests
from openpype.lib import Logger, is_running_from_build
from openpype.pipeline import Anatomy
from openpype.pipeline.colorspace import get_imageio_config
logger = Logger.get_logger(__name__)
# Regular expression that allows us to replace the frame numbers of a file path
# with any string token
RE_FRAME_NUMBER = re.compile(
r"(?P<prefix>^(.*)+)\.(?P<frame>\d+)\.(?P<extension>\w+\.?(sc|gz)?$)"
)
def create_metadata_path(instance_data):
# Ensure output dir exists
output_dir = instance_data.get(
"publishRenderMetadataFolder", instance_data["outputDir"]
)
try:
if not os.path.isdir(output_dir):
os.makedirs(output_dir)
except OSError:
# directory is not available
logger.warning("Path is unreachable: `{}`".format(output_dir))
metadata_filename = "{}_{}_{}_metadata.json".format(
datetime.datetime.now().strftime("%d%m%Y%H%M%S"),
instance_data["asset"],
instance_data["subset"]
)
return os.path.join(output_dir, metadata_filename)
def replace_frame_number_with_token(path, token):
return RE_FRAME_NUMBER.sub(
r"\g<prefix>.{}.\g<extension>".format(token), path
)
def get_representations(
instance_data,
exp_representations,
add_review=True,
publish_to_sg=False
):
"""Create representations for file sequences.
This will return representation dictionaries of expected files. There
should be only one sequence of files for most cases, but if not - we create
a representation for each.
If the file path given is just a frame, it
Arguments:
instance_data (dict): instance["data"] for which we are
setting representations
exp_representations (dict[str:str]): Dictionary of expected
representations that should be created. Key is name of
representation and value is a file path to one of the files
from the representation (i.e., "exr": "/path/to/beauty.1001.exr").
Returns:
list of representations
"""
anatomy = Anatomy(instance_data["project"])
representations = []
for rep_name, file_path in exp_representations.items():
rep_frame_start = None
rep_frame_end = None
ext = None
# Convert file path so it can be used with glob and find all the
# frames for the sequence
file_pattern = replace_frame_number_with_token(file_path, "*")
representation_files = glob.glob(file_pattern)
collections, remainder = clique.assemble(representation_files)
# If file path is in remainder it means it was a single file
if file_path in remainder:
collections = [remainder]
frame_match = RE_FRAME_NUMBER.match(file_path)
if frame_match:
ext = frame_match.group("extension")
frame = frame_match.group("frame")
rep_frame_start = frame
rep_frame_end = frame
else:
rep_frame_start = 1
rep_frame_end = 1
ext = os.path.splitext(file_path)[1][1:]
elif not collections:
logger.warning(
"Couldn't find a collection for file pattern '%s'.",
file_pattern
)
continue
if len(collections) > 1:
logger.warning(
"More than one sequence find for the file pattern '%s'."
" Using only first one: %s",
file_pattern,
collections,
)
collection = collections[0]
if not ext:
ext = collection.tail.lstrip(".")
staging = os.path.dirname(list(collection)[0])
success, rootless_staging_dir = anatomy.find_root_template_from_path(
staging
)
if success:
staging = rootless_staging_dir
else:
logger.warning(
"Could not find root path for remapping '%s'."
" This may cause issues on farm.",
staging
)
if not rep_frame_start or not rep_frame_end:
col_frame_range = list(collection.indexes)
rep_frame_start = col_frame_range[0]
rep_frame_end = col_frame_range[-1]
tags = []
if add_review:
tags.append("review")
if publish_to_sg:
tags.append("shotgridreview")
files = [os.path.basename(f) for f in list(collection)]
# If it's a single file on the collection we remove it
# from the list as OP checks if "files" is a list or tuple
# at certain places to validate if it's a sequence or not
if len(files) == 1:
files = files[0]
rep = {
"name": rep_name,
"ext": ext,
"files": files,
"frameStart": rep_frame_start,
"frameEnd": rep_frame_end,
# If expectedFile are absolute, we need only filenames
"stagingDir": staging,
"fps": instance_data.get("fps"),
"tags": tags,
}
if instance_data.get("multipartExr", False):
rep["tags"].append("multipartExr")
# support conversion from tiled to scanline
if instance_data.get("convertToScanline"):
logger.info("Adding scanline conversion.")
rep["tags"].append("toScanline")
representations.append(rep)
solve_families(instance_data, add_review)
return representations
def get_colorspace_settings(project_name):
"""Returns colorspace settings for project.
Returns:
tuple | bool: config, file rules or None
"""
config_data = get_imageio_config(
project_name,
host_name="nuke", # temporary hack as get_imageio_config doesn't support grabbing just global
)
# in case host color management is not enabled
if not config_data:
return None
return config_data
def set_representation_colorspace(
representation,
project_name,
colorspace=None,
):
"""Sets colorspace data to representation.
Args:
representation (dict): publishing representation
project_name (str): Name of project
config_data (dict): host resolved config data
file_rules (dict): host resolved file rules data
colorspace (str, optional): colorspace name. Defaults to None.
Example:
```
{
# for other publish plugins and loaders
"colorspace": "linear",
"config": {
# for future references in case need
"path": "/abs/path/to/config.ocio",
# for other plugins within remote publish cases
"template": "{project[root]}/path/to/config.ocio"
}
}
```
"""
ext = representation["ext"]
# check extension
logger.debug("__ ext: `{}`".format(ext))
config_data = get_colorspace_settings(project_name)
if not config_data:
# warn in case no colorspace path was defined
logger.warning("No colorspace management was defined")
return
logger.debug("Config data is: `{}`".format(config_data))
# infuse data to representation
if colorspace:
colorspace_data = {"colorspace": colorspace, "config": config_data}
# update data key
representation["colorspaceData"] = colorspace_data
def solve_families(instance_data, preview=False):
families = instance_data.get("families")
# if we have one representation with preview tag
# flag whole instance_data for review and for ftrack
if preview:
if "review" not in families:
logger.debug('Adding "review" to families because of preview tag.')
families.append("review")
instance_data["families"] = families
And finally the abstraction of Deadline so I can submit any plugin job using the same function:
# Default Deadline job
DEFAULT_PRIORITY = 50
DEFAULT_CHUNK_SIZE = 9999
DEAFAULT_CONCURRENT_TASKS = 1
def payload_submit(
plugin,
plugin_data,
batch_name,
task_name,
group="",
comment="",
priority=DEFAULT_PRIORITY,
chunk_size=DEFAULT_CHUNK_SIZE,
concurrent_tasks=DEAFAULT_CONCURRENT_TASKS,
frame_range=None,
department="",
extra_env=None,
response_data=None,
):
if not response_data:
response_data = {}
frames = "0" if not frame_range else f"{frame_range[0]}-{frame_range[1]}"
payload = {
"JobInfo": {
# Top-level group name
"BatchName": batch_name,
# Job name, as seen in Monitor
"Name": task_name,
# Arbitrary username, for visualisation in Monitor
"UserName": getpass.getuser(),
"Priority": priority,
"ChunkSize": chunk_size,
"ConcurrentTasks": concurrent_tasks,
"Department": department,
"Pool": "",
"SecondaryPool": "",
"Group": group,
"Plugin": plugin,
"Frames": frames,
"Comment": comment or "",
# Optional, enable double-click to preview rendered
# frames from Deadline Monitor
# "OutputFilename0": preview_fname(render_path).replace("\\", "/"),
},
"PluginInfo": plugin_data,
# Mandatory for Deadline, may be empty
"AuxFiles": [],
}
if response_data.get("_id"):
payload["JobInfo"].update(
{
"JobType": "Normal",
"BatchName": response_data["Props"]["Batch"],
"JobDependency0": response_data["_id"],
"ChunkSize": 99999999,
}
)
# Include critical environment variables with submission
keys = [
"AVALON_ASSET",
"AVALON_TASK",
"AVALON_PROJECT",
"AVALON_APP_NAME",
"OCIO",
"USER",
"OPENPYPE_SG_USER",
]
# Add OpenPype version if we are running from build.
if is_running_from_build():
keys.append("OPENPYPE_VERSION")
environment = dict(
{key: os.environ[key] for key in keys if key in os.environ},
**legacy_io.Session,
)
if extra_env:
environment.update(extra_env)
payload["JobInfo"].update(
{
"EnvironmentKeyValue%d"
% index: "{key}={value}".format(
key=key, value=environment[key]
)
for index, key in enumerate(environment)
}
)
plugin = payload["JobInfo"]["Plugin"]
logger.info("using render plugin : {}".format(plugin))
logger.info("Submitting..")
logger.info(json.dumps(payload, indent=4, sort_keys=True))
url = "{}/api/jobs".format(constants.DEADLINE_URL)
response = requests.post(url, json=payload, timeout=10)
if not response.ok:
raise Exception(response.text)
return response.json()